INVITED TALKS
No more collostructions, please! (At least not the traditional type …)
Stefan Th. GRIES
(University of California, Santa Barbara, USA)
The family of members making ‘collostructional analysis’, in particular collexeme analysis and distinctive collexeme analysis, have been a quite successful addition to the intersection of corpus linguistics and Construction Grammar and cognitive/usage-based linguistics. Ever since 2003/2004, for both Anatol Stefanowitsch and myself, the two ‘founding papers’ are the by far most widely cited studies and collostructional methods have been used in a huge variety of settings, with many languages and corpora, and with many different goals. That being said, one should also admit that they are 20+ years old and that linguistics in general and cognitive/usage-based linguistics in particular has evolved to become much more advanced and quantitative. Thus, while basic collostructional studies might still have some exploratory value, I have to say that I prefer that such basic studies probably should either go extinct or, better, evolve as well. Over the last few years, I made a variety of suggestions about how to make collostructional approaches fit ‘the new world’ and this talk bundles them together. More specifically, I will:
- outline 6 different ways in which the traditional approach must now be considered less than ideal;
- note how studies that just follow the traditional approach today should be improved (with improvements rank-ordered in terms of ease-of-implementation and importance).
The hope is that, to the extent that there is still an interest in corpus-linguistic association measures in Construction Grammar, these recommendations can ensure that such studies do justice to the new, more statistical environment of the 2020s and the more advanced theoretical refinement of Construction Grammar and cognitive/usage-based linguistics.
Constructions with crossed syntactic dependencies show elevated lexical cohesion: The compensatory collocation hypothesis
Martin HILPERT
(Université de Neuchâtel, Switzerland)
Natural languages avoid syntactic structures with crossed syntactic dependencies. To the extent that such structures nonetheless occur, they have been explained as the result of competing motivations, such as dependency length minimization, the facilitation of incremental language processing, or the preservation of the given-before-new principle. In this talk, I discuss a construction from English for which these explanations do not hold. In sentences such as He has written a good enough story to attract attention, dependency length is not minimized, incremental processing is not at issue, and alternative syntactic patterns allow the same ordering of given and new information. My talk aims to identify a different motivating factor. I present the compensatory collocation hypothesis, which states that when speakers choose a non-projective structure, they tend to attenuate the processing costs for the hearer by choosing lexical items that are semantically cohesive. Data from the COHA substantiates this idea. Compared to alternative constructions with a projective syntactic structure, examples with crossed dependencies exhibit word combinations with relatively higher collocational strength.
Functional Linguistics Meets Big Data
Serge SHAROFF
(University of Leeds, UK)
The talk discusses reciprocal benefits between Functional Linguistics and Natural Language Processing. NLP enables large-scale functional analysis across millions of texts, revealing register-specific patterns, for example, in negation, nominalisation or passivisation. Conversely, the functional framework provides theoretically-grounded metalanguage for explaining neural model predictions, addressing interpretability challenges in modern AI systems.
PRESENTATIONS
Modifier Ordering and Lexicogrammatical Structure in Ògè Nominal Phrases
Priscilla ADENUGA
(Independent Researcher, Wiesbaden, Germany)
How languages encode adjectival meaning varies considerably across grammatical systems. This paper examines nominal adjectival modification in Ògè, an underdescribed Benue-Congo language spoken in southwestern Nigeria, where adjectival meanings are expressed through nominal elements rather than through a distinct adjective class. Adopting a lexicogrammatical perspective in which lexis and grammar are viewed as interacting along a continuum rather than forming separate modules, the study addresses the following research questions: (i) how are adjectival meanings encoded within the Ògè noun phrase, (ii) what ordering constraints regulate the distribution of nominal adjectival modifiers (NAMs), and (iii) what do these patterns reveal about the interaction between lexical classes and grammatical linearisation.
The analysis is based on a morphosyntactically annotated corpus of approximately 4,000–5,000 tokens, consisting primarily of recorded folktales and supplemented by elicited examples and conversational narrative data, from which instances of nominal adjectival modifiers are identified for analysis. Nominal constructions were examined for modifier type, positional distribution, and co-occurrence patterns. The study combines structural analysis with corpus inspection and targeted elicitation in order to identify systematic constraints governing modifier ordering and interpretation. The analysis is primarily qualitative, focusing on structural and semantic possibilities rather than on frequency distributions.
The data show that adjectival meanings in Ògè are realised through nominal adjectival modifiers (NAMs), i.e. nominal elements functioning as modifiers within the noun phrase (cf. Dixon 1982, 2010). These modifiers occur in strictly prenominal position and must be followed by the head noun. Reversal of the modifier–noun order results in ungrammaticality, demonstrating that modification is grammatically constrained rather than freely lexical. When multiple modifiers occur, the language exhibits preferred ordering patterns linked to semantic subclass, such as SIZE > COLOR and QUALITY > SHAPE. These sequences represent the unmarked configuration of stacked modifiers and are consistent with cross-linguistic observations on adjective ordering (cf. Cinque 2010, 2014).
Alternative orders are possible but require prosodic marking and yield contrastive or emphatic interpretations. For instance, reversing the SIZE > COLOR sequence produces an interpretation in which the first modifier receives focal emphasis. This contrast suggests that modifier ordering in Ògè is not arbitrary but reflects a structured interaction between lexical semantic class and grammatical linearisation. The system therefore distinguishes between a basic lexicogrammatical ordering and a marked configuration associated with discourse prominence. Further evidence for the specialised status of NAMs comes from their distributional restrictions: these elements are grammatical only in attributive position and cannot occur in predicative or relative clause environments in the same form.
Taken together, the Ògè data demonstrate that modifier ordering emerges from systematic interaction between lexical subclass and grammatical structure. The analysis provides empirical support for understanding lexicogrammar as a domain in which lexical distinctions constrain syntactic linearisation. More broadly, the findings contribute to typological discussions of nominal modification and adjective ordering across languages with restricted adjectival classes and illustrate how corpus-informed structural analysis can make lexicogrammatical constraints visible in underdescribed languages.
References
Cinque, G. (2010). The syntax of adjectives: A comparative study (Vol. 57). MIT press.
Cinque, G. (2014). The semantic classification of adjectives. A view from syntax. Studies in Chinese Linguistics, 35(1), 3-32.
Dixon, R. M. (2010). Basic linguistic theory volume 2: Grammatical topics (Vol. 2). OUP Oxford.
Dixon, R. M. (2010). Where have all the adjectives gone?: And other essays in semantics and syntax (Vol. 107). Walter de Gruyter.
Dryer, M. S. (2013). Order of adjective and noun. The world atlas of language structures online.
Lexical and Lexicogrammatical Sophistication across B2 and C1 Levels: A Corpus-Based Analysis of English Exam Texts
Deise AMARAL & Simone SARMENTO
(Universidade Federal do Rio Grande do Sul, Brazil)
This study adopts a learner corpus perspective to investigate how lexical and lexicogrammatical sophistication distinguishes B2 and C1 examination essays. In high-stakes language assessment contexts, the distinction between these adjacent proficiency levels is largely associated with the range, precision, and appropriateness of learners’ lexical and phraseological resources (Brown, 2006; Hawkey & Barker, 2004). Assessment scales frequently refer to idiomaticity, collocational control, and lexical sophistication (Biber & Gray, 2013; Council of Europe, 2020; IELTS, 2023), but these constructs are not always clearly defined or consistently operationalised in rating practices.
The study addresses two related questions. First, which corpus-derived measures of lexical and phraseological complexity help distinguish B2 from C1 writing? Second, what lexicogrammatical patterns emerge from strongly associated recurrent word combinations (n-grams) in these levels. To answer the questions, we analyse a corpus of 327 proficiency-rated examination essays, using a cross-sectional design that compares texts rated at B2 and C1. The analysis draws on a multidimensional model of lexical and phraseological complexity, focusing primarily on sophistication while also considering diversity and density (Kyle, 2019; Paquot, 2018).
Proficiency discrimination is operationalised through 14 corpus-derived indices, including frequency profiles, word and bigram diversity, content-word and function-word relations, and collocational strength measured through MI-scores. The relevance to lexicogrammar lies particularly in the analysis of content-function-word combinations, which capture not only lexical choice but also recurring grammatical and discourse-organisational patterns. Before analysis, spelling variants were standardised and the corpus was annotated to ensure more reliable corpus-based measures and to avoid artificially inflated type-based indices. Quantitative comparisons were conducted across B2 and C1 texts, followed by binary logistic regression to identify which dimensions contributed most strongly to proficiency-level prediction. These results were complemented by qualitative concordance analyses of high-MI bigrams with association scores above 7, which were operationalised as indicators of phraseological sophistication.
Results show that C1 texts display higher levels of lexical and phraseological sophistication, as well as greater lexical density and diversity, than B2 texts. With the exception of lexical diversity, the main complexity dimensions contributed to proficiency-level discrimination. Concordance analyses suggest that advanced writing is characterised less by idiomaticity in the narrow sense than by precise, topic-relevant, and contextually-appropriate lexical co-selection of predominantly content-word combinations. Idiomatic expressions were infrequent overall and appeared more often in B2 texts, challenging the assumption that idiomaticity is a straightforward marker of higher proficiency. The analysis also shows that recurrent content-function-word combinations play an important role in genre realisation and discourse organisation.
By combining quantitative corpus measures with qualitative concordance analysis, this study clarifies how lexical and lexicogrammatical sophistication operates across adjacent advanced CEFR levels. The findings contribute to learner corpus research and language assessment by offering empirically grounded insights into how lexical and phraseological criteria can be operationalised in rating scales and pedagogical contexts. They also highlight the importance of recurrent, topic-relevant, and genre-sensitive word combinations in advanced writing.
References
Biber, D., & Gray, B. (2013). Discourse characteristics of writing and speaking task types on the TOEFL iBT® test: A lexico-grammatical analysis. TOEFL iBT® Research reports. ETS.
Brown, A. (2006). Candidate discourse in the revised IELTS Speaking Test. In P. Mcgovern & S. Walsh (Eds.). IELTS Research Reports, Volume 6. IELTS Australia e British Council, 71-89. https://s3.eu-west-2.amazonaws.com/ielts-web-static/production/Research/candidate-discourse-in-revised-ielts-speaking-test-brown-2006.pdf
Council of Europe (2020). Common European Framework of Reference for Languages: learning, teaching, assessment – Companion volume. Council of Europe Publishing. www.coe.int/lang-cefr .
Hawkey, R., & Barker, F. (2004). Developing a common scale for the assessment of writing. Assessing Writing, 9(2), 122-159. https://doi.org/10.1016/j.asw.2004.06.001
IELTS™. (2023). Writing Band Descriptors. IELTS.org. British Council, IDP: IELTS Australia and Cambridge University Press and Assessment. https://s3.eu-west-2.amazonaws.com/ielts-web-static/production/Guides/ielts-writing-band-descriptors.pdf
Kyle, K. (2019). Measuring Lexical Richness. In S. Webb (Ed.), The Routledge handbook of vocabulary studies (pp. 454-476). Routledge. https://doi.org/10.4324/9780429291586-29
Paquot, M. (2018). Phraseological competence: A missing component in university entrance language tests? Insights from a study of EFL learners’ use of statistical collocations. Language Assessment Quarterly, 15(1), 29-43. https://doi.org/10.1080/15434303.2017.1405421
Task Effects on Pragmatic Construction Use in Adolescent Argumentative Writing
Dilay CANDAN
(Georgia State University, USA)
This corpus-based study investigates how Grade 8 students strategically adapt pragmatic constructions (form-function pairings at the lexis-grammar interface) to differing argumentative task demands, and whether large-scale scoring practices reflect these task-sensitive lexicogrammatical patterns. Drawing on the PERSUADE 2.0 corpus (Crossley et al., 2024), which contains 9,629 essays (independent n = 8,046, text-dependent n = 1,583) all holistically scored 1 to 6 via SAT-aligned rubrics, the analysis targets three construction families central to argumentation. These include first-person epistemic stance markers (e.g., “I believe that”), concessive structures (e.g., “Although some argue,” “Despite views”), and reader engagement devices (e.g., “We must recognize”). Independent tasks emphasize personal authority and reasoning from prior knowledge, while text-dependent tasks demand source synthesis and the integration of multiple voices, producing distinct rhetorical conditions that usage-based theory predicts will elicit divergent construction profiles.
Two research questions guide the work. RQ1 asks to what extent the frequencies of epistemic stance, concessive constructions, and reader engagement markers differ between independent and text-dependent tasks. RQ2 examines whether these constructions predict holistic writing quality and whether task type moderates these relationships. We hypothesize task-conditioned distributions if pragmatic constructions are context-sensitive units learned through usage (Goldberg, 2006; Ellis et al., 2016), with construct-aligned scoring showing corresponding task-dependent effects. The theoretical orientation integrates Hyland’s (2005) metadiscourse framework with Construction Grammar, treating these patterns lexicogrammatically, since recurrent syntactic templates realize interpersonal functions whose frequencies shift with communicative demands.
Constructions were operationalized through precise patterns (e.g., epistemic stance as I/We + verb + that/to-clause), with precision of 90 to 94% and recall of 85 to 91% across 100 manually validated instances per construction type, normalized per 1,000 words. RQ1 employed MANOVA with task as predictor and length as a covariate, yielding a significant multivariate effect (Wilks’ Λ = 0.922, F = 272.33, p < .001, ηp² = 0.027). Independent essays showed higher epistemic markers (M = 4.28 vs. 1.56 per 1,000 words; d = 0.54, p < .001), text-dependent essays showed higher concessive constructions (M = 2.12 vs. 0.82; d = −0.55, p < .001), and reader engagement remained stable across tasks (M = 8.69 vs. 8.93, p = .386).
For RQ2, hierarchical regression (quality ~ length + task + constructions + interactions; final R² = .413) revealed that epistemic markers negatively predicted scores (β = −.157, p < .001) and concessives positively predicted scores (β = .061, p < .05) uniformly across both task types. No significant task × construction interactions emerged for either feature (p > .05), indicating that raters applied consistent evaluation criteria despite students’ task-sensitive distributional behavior. Critically, pragmatic constructions accounted for substantially more variance in writing quality for independent essays (R² = .558) than for text-dependent essays (R² = .103), suggesting that raters weight these features differently across task contexts even when the direction of their effects remains stable. Reader engagement showed a crossover interaction (p < .05), with the feature negatively associated with quality in independent writing but positively associated in text-dependent writing.
These findings demonstrate adolescent writers’ task-sensitive lexicogrammar. Epistemic boosts signal authorial presence in independent contexts, while concessives enable dialogicity amid competing sources in text-dependent ones, providing empirical support for constructions as context-bound form-function units. However, the uniformity of scoring for epistemic and concessive constructions highlights a construct misalignment, since raters appear to undervalue task-appropriate pragmatic adaptation. The R² disparity further suggests that existing rubrics may be better calibrated for independent than for source-based writing, with direct implications for automated scoring systems trained on pragmatic features. The study advances corpus methods for adolescent writing development and argues for task-specific rubric criteria, rater training, and differentiated automated scoring calibration. Future work could explore collocational priming or diachronic shifts in pragmatic construction use.
References
Crossley, S. A., Tian, Y., Baffour, P., Franklin, A., Benner, M., & Boser, U. (2024). A large-scale corpus for assessing written argumentation: PERSUADE 2.0. Assessing Writing, 61, 100865. https://doi.org/10.1016/j.asw.2024.100865
Ellis, N. C., Römer, U., & O’Donnell, M. B. (2016). Usage-based approaches to language learning and teaching. In B. VanPatten & J. Williams (Eds.), Theories in second language acquisition: An introduction (3rd ed., pp. 75–93). Routledge.
Goldberg, A. E. (2006). Constructions at work: The nature of generalization in language. Oxford University Press.
Hyland, K. (2005). Metadiscourse: Exploring interaction in writing. Continuum.
Past Tense Use in L1 and L2 Spanish Narratives: A Corpus-Based Study of Form, Meaning, and Context
Maura CRUZ ENRÍQUEZ1, Anahí Alba DE LA FUENTE2 & François LAREAU2
(1Université TÉLUQ, Canada; 2Université de Montréal, Canada)
This paper presents an ongoing corpus-based study on the use of past tense forms in narratives produced by native Spanish (L1) speakers and francophone learners of Spanish as a second language (L2). The project is guided by two main objectives. First, it seeks to better understand the developmental progression of past tense usage from a semantic-pragmatic perspective, emphasizing the role of context in the use of verbal forms. Particular attention is paid to how learners progressively mobilize verbal forms to express temporal, aspectual, and interpretative distinctions in narrative contexts, from lower proficiency levels (A2) to near-native competence. In this perspective, tense is analyzed as part of a broader system in which meaning emerges from the interaction between morphology, lexical aspect, argument structure, and discourse function. Second, the project aims to generate both quantitative and qualitative data to support the future development of automatic analysis models capable of integrating morphosyntactic and semantic-pragmatic dimensions. To this end, a large corpus of L1 and L2 Spanish narratives is being compiled from university language courses in Quebec, complemented by data from existing learner corpora such as CEDEL2.
The theoretical framework is based on the Function-meaning-form model (Cruz Enríquez, 2019), which integrates insights from functional linguistics (M. Halliday, 1985; M. A. K. Halliday & Matthiessen, 2014), and enunciation theory (Weinrich, 1973). The model accounts for three key dimensions in the interpretation of verbal forms: tense, grammatical aspect, and lexical aspect, as well as distinctions between narrative and commentative discourse.
Methodologically, the project adopts a hybrid approach combining automatic and manual annotation. The corpus is first processed using Python and SpaCy to extract morphosyntactic information, including clause structure, verbal forms, and temporal markers. Additional rule-based procedures and lexical resources are used to approximate higher-level categories, such as process type and narrative function. Process type is partly informed by data from the ADESSE database (García-Miguel, 2002), which provides detailed syntactic-semantic information on Spanish verbs, including their classification into process types and their argument structure patterns. This resource allows us to associate verbal forms with typical semantic classes (e.g. material, mental, perceptual processes) and to consider verb–argument combinatorics when approximating lexical aspect and meaning in context.
In a second stage, manual annotation is carried out to validate and refine the automatic output, focusing on semantic-pragmatic interpretation, ambiguity resolution, and error analysis. The annotation scheme is iteratively improved as new patterns and sources of error are identified. Native speaker data are analyzed first, followed by advanced learners and progressively lower levels, enabling a stepwise refinement of both the analytical framework and the annotation procedures.
Results from the first stage of analysis are drawn from a manually annotated subset of approximately 27,000 words, consisting of oral and written narratives produced by 20 native speakers and 20 advanced L2 learners in an elicited storytelling task based on a film excerpt. This initial dataset constitutes the first stage of the broader corpus currently under construction and serves to guide the development of the annotation scheme and subsequent large-scale analyses. Bayesian mixed-effects models reveal systematic differences between groups in the distribution of past tense forms in background contexts.
For the expression of progressive meaning, L2 learners show a higher probability of using analytic constructions (e.g. estaba cantando, cantando), whereas native speakers favor the imperfect (cantaba), particularly in contexts introduced by perception verbs such as ver (e.g., Vio que la chica robaba una barra de pan), thereby exploiting its polysemy across discourse contexts. For the expression of anteriority in the background, learners tend to rely more on pluperfect forms (había cantado), while native speakers extend the use of the preterite (e.g. Dijo que la chica robó un pan) to this temporal relation. Effects of modality (oral vs written) appear comparatively weak. Overall, these findings suggest that observed differences between advanced learners and native speakers are better explained in terms of differences in the discourse-pragmatic control of verbal polysemy than by purely morphosyntactic limitations.
These results inform the next stage of the project, since the manual analysis makes it possible to identify general tendencies and systematic differences between groups in the way temporal relations are expressed. These observations help anticipate the kinds of patterns that need to be captured in a hybrid or automatic approach, especially when dealing with learner data across proficiency levels. This provides a basis for developing more robust procedures for the automatic analysis of tense–aspect usage in L1 and L2 narrative corpora.
References
Cruz Enríquez, M. (2019). Función-significado-forma: Un modelo para el estudio de los tiempos verbales del español. https://papyrus.bib.umontreal.ca/xmlui/handle/1866/22635
García-Miguel, J. M. (2002). ADESSE: Base de datos de verbos, alternancias de diátesis y esquemas sintáctico‑semánticos del español (Universidade de Vigo) [Jeu de données]. https://adesse.uvigo.es
Halliday, M. (1985). An Introduction to Functional Grammar ((1ra ed.).). Edward Arnold.
Halliday, M. A. K., & Matthiessen, C. (2014). An introduction to functional grammar. Routledge.
Weinrich, H. (1973). Le Temps : Le récit et le commentaire. Éditions du Seuil.
Generic and structural patterns of behaviour of quadrisyllabic idioms in Mandarin
Yuqing DING & Andrew HARDIE
(Shanghai Jiao Tong University, China; Lancaster University, UK)
In Chinese lexicology, the term chéngyǔ refers to a distinctive category of compound words in Chinese, richly imbued with cultural significance. The Modern Chinese Dictionary, for example, characterises chéngyǔ as predominantly four-character idioms that are typically derived from literary or historical sources, structurally invariable and semantically opaque, conveying concise, often metaphorical meanings. An example chéngyǔ which possesses all these qualities is 名存实亡 míngcúnshíwáng ‘name exists, reality dies = exist in name only’. As a linguistic term, chéngyǔ is variously translated as “quadrisyllabic idioms/idiomatic expressions” or simply left untranslated in English-medium literature on this class of item. But despite the terminological difficulty, most authorities seem to agree that chéngyǔ is a narrowly definable category of short, fully fixed idiom, typically treated as single tokens in word segmentation and thus effectively compound words.
Despite significant research on the internal structure and semantic compositionality of chéngyǔ, particularly in psycholinguistics and pedagogical research, systematic corpus-based descriptive analyses remain relatively scarce. This preliminary study intends to contribute to filling this gap in the literature by examining (a) chéngyǔ’s usage distribution across different genres and (b) chéngyǔ’s syntactic behaviour.
We employ the Lancaster Corpus of Mandarin Chinese (LCMC), a one-million-word balanced written Chinese corpus. One key methodological problem that we faced is the issue of how to operationalise the boundary between chéngyǔ and other kinds of long compound or fixed idiom (categories often blurred in theoretical discussions). Having found no theoretically motivated operationalisation, we develop an “inclusive definition” on pragmatic bases. First, all four-character word types in the LCMC were extracted. Two native speakers then independently annotated the list, to separate chéngyǔ from non-chéngyǔ. In cases of disagreement or mutual uncertainty, online dictionaries of chéngyǔ were consulted, and moreover, in the interests of inclusivity, deferred to these sources when they differed from the initial division.
According to this process, we ultimately identified 5,567 chéngyǔ tokens (2,649 types) in the corpus. We then approached this data through (a) frequency distribution, to investigate differential use across genres; (b) a full-concordance grammatical analysis identifying syntactic function in context. These descriptive analyses are founded in the theoretical presumption that a class of lexis defined by its internal structure and etymology may, just as any other lexical class, present behaviour at any of a number of linguistic levels associated with the class: that is, grammatical phenomena bound to a lexical category.
First, the frequency distribution of chéngyǔ types in written Mandarin closely follows a Zipfian pattern, indicating that a small number of chéngyŭ are highly conventionalised and frequently used, whereas the majority occur only rarely. Hence, because of the corpus size, all types at the lower end of the distribution are underrepresented; a larger corpus would increase the number of examples for rarer chéngyǔ and allow a more robust test of the Zipfian pattern.
Second, we also found substantial and statistically significant variation in the aggregate frequency of chéngyǔ across genres. Similar variation is observable for the distribution of individual types. For instance, chéngyǔ are markedly more prevalent in the LCMC text categories of Press and Fiction, than in General Prose and Learned. From the analysis of grammatical structures, we discovered that most common syntactic function of chéngyǔ is predicative, and they are particularly likely to form complete, as opposed to partial, predicates as single words. Also common is modifier function, both adnominal and adverbial. Nominal use is less frequent. Interestingly, chéngyǔ with nominal function prefer object role over subject (respectively 57% and 20% of instances).
Although descriptive in nature, these findings have potential pedagogical implications for teaching Chinese as a second or foreign language. In that context, it is common for the category of chéngyǔ to be taught explicitly; our findings highlight the importance of incorporating matters of genre and syntactic context when introducing chéngyǔ to learners. By establishing a clear baseline of knowledge on the authentic usage of chéngyǔ, this study paves the way for more nuanced theoretical and applied research on this class of Chinese lexis. The relatively modest size of the LCMC makes it impossible to draw quantitative conclusions about specific chéngyǔ types; a larger corpus would be beneficial for increasing token counts for low-frequency chéngyǔ, strengthening the observed distributional patterns, and enabling type-specific analysis. Nevertheless, the current corpus still provides a sufficient number of valid examples for the overall syntactic distribution and analysis of chéngyǔ.
Lexicogrammatical Variation in English: A Corpus-based Exploration of the Relationship Between Syntactic Complexity and Lexical Diversity Across Text Types
Anissa Kawther FELOUS
(University of Souk Ahras, Algeria)
Syntactic complexity and lexical diversity are among the most widely investigated dimensions in corpus-based research. However, the relationship between them is largely unexamined as most studies typically focus on one dimension in isolation rather than examining their interaction directly. This paper reports on a work in progress that addresses this gap in the literature by examining the extent to which syntactic complexity and lexical diversity correlate within and across different English text types. Moreover, this study contributes to lexicogrammatical research by treating syntactic complexity and lexical diversity as potentially co-varying properties of the lexicogrammatical continuum. The central research questions are: (1) To what extent do syntactic complexity measures correlate with lexical diversity measures? And (2) Do the direction and magnitude of those relationships vary systematically across genres?
The current corpus comprises 483 texts (and 838249 tokens) across eight text types: research abstracts, journal articles, encyclopedia entries, essays, news reports, textbook texts, sections of theses, and informal digital texts including blog posts and social media posts published online. Plans to expand the corpus significantly are underway, and the present findings are offered as preliminary results. Syntactic complexity is operationalized through five T-unit based (Hunt, 1965; Lu, 2010) measures calculated using the Tool for Automatic Analysis of Syntactic Sophistication and Complexity (TAASSC) (Kyle, 2016): Mean Length of T-unit (MLT), Clauses per T-unit (C/T), Dependent Clauses per T-unit (DC/T), Coordinate Phrases per T-unit (CP/T), and Complex Nominals per T-unit (CN/T). Lexical diversity is measured using two indices shown to be robust to text length variation (Zenker & Kyle, 2021): Moving Average Type Token Ratio (MATTR) (Covington & McFall, 2010) and Measure of Textual Lexical Diversity (MTLD) (McCarthy & Jarvis, 2010). Both of the lexical diversity measures were calculated using the Tool for Automatic Analysis of Lexical Diversity (TAALED) (Kyle, Crossley & Jarvis, 2020). Correlations were computed using the Statistical Package for Social Sciences (SPSS).
The theoretical orientation is grounded in Halliday’s (1991) conception of lexicogrammar as a continuum in which grammatical and lexical patterning represent complementary perspectives on a unified resource. It also draws on Biber’s (1988) register framework, which predicts that distinct situational parameters place distinct but not necessarily aligned demands on syntactic and lexical choices.
For the overall corpus, and after applying the Bonferroni correction to account for 10 correlation comparisons (alpha = 0.05/10 = 0.005), no statistically significant correlations were found between any of the syntactic complexity and lexical diversity measures. Those results indicate that the two dimensions do not systematically co-vary across the corpus as a whole.
As for the genre specific analyses, and after the application of the Bonferroni correction to account for the multiple comparisons, specifically ten pairs of lexical diversity and syntactic complexity measures across eight genres, resulting in 80 correlation comparisons (alpha = 0.05/80= 0.000625), the preliminary results point to a dissociation between the two dimensions. The syntactic complexity and lexical diversity measures show no significant correlation with each other in most genres. However, a notable exception emerges in textbook texts as they show a positive moderate and statistically significant correlation. Other genres showed some patterns that were significant prior to the correction to the significance value, but they did not withstand the multiple comparisons correction. Those results point to tentative register sensitive tendencies that require further investigation.
Those findings suggest that, while lexical diversity and syntactic complexity appear to operate as independent dimensions both across the corpus and within the most of the types of written English texts, specific genres, such as the textbook genre, present a context wherein they significantly co-vary.
Overall, these preliminary findings contribute to corpus-based lexicogrammar research by empirically examining the interaction between the two dimensions that are frequently investigated separately in corpus research. However, the patterns observed warrant further investigation with an expanded corpus to enhance statistical power and to validate and elaborate upon the full range of those patterns across genres.
References
Biber, D. (1988). Variation across Speech and Writing. In Cambridge University Press eBooks. https://doi.org/10.1017/cbo9780511621024
Covington, M. A., & McFall, J. D. (2010). Cutting the gordian knot: The Moving-Average Type–Token Ratio (MATTR). Journal of Quantitative Linguistics, 17(2), 94–100. https://doi.org/10.1080/09296171003643098
Halliday, M. a. K. (1991). Corpus studies and probabilistic grammar. In K. Aijmer & B. Altenberg (Eds.), English Corpus Linguistics (1st ed.). Routledge. https://doi.org/10.4324/9781315845890
Hunt, K. W. (1965). Grammatical structures written at three grade levels.
Kyle, K., Crossley, S. A., & Jarvis, S. (2020). Assessing the validity of lexical diversity indices using direct judgements. Language Assessment Quarterly, 18(2), 154–170. https://doi.org/10.1080/15434303.2020.1844205
Lu, X. (2010). Automatic analysis of syntactic complexity in second language writing. International Journal of Corpus Linguistics, 15(4), 474–496. https://doi.org/10.1075/ijcl.15.4.02lu
McCarthy, P. M., & Jarvis, S. (2010). MTLD, vocd-D, and HD-D: A validation study of sophisticated approaches to lexical diversity assessment. Behavior Research Methods, 42(2), 381–392. https://doi.org/10.3758/brm.42.2.381
Norris, J. M., & Ortega, L. (2009). Towards an organic approach to investigating CAF in instructed SLA: the case of complexity. Applied Linguistics, 30(4), 555–578. https://doi.org/10.1093/applin/amp044
Zenker, F., & Kyle, K. (2021). Investigating minimum text lengths for lexical diversity indices. Assessing Writing, 47, 100505. https://doi.org/10.1016/j.asw.2020.100505
Phraseological shift as a signature of semantic change: the case of French courage
Quentin FELTGEN
(Ghent University, Belgium)
The French courage has undergone, since the twelfth century, a considerable meaning shift. In Old French, courage is highly polysemous, and refers both to the location of one’s feelings (with phrasemes like en son courage, literally ‘in one’s courage’, or dire son courage, ‘speak one’s heart’) and to a specific quality that can take a variety of values: one can be mauvais de courage (‘of a vile heart’) or host guests de bon courage (‘with a good heart’). Most of these uses have been taken over by cœur (‘heart’), with which it is frequently encountered in the “synonymic binomial” construction (Siouffi 2012), especially in the 16th century (e.g. Je m’en vois faire ung voiage, De bon cueur et bon couraige, ‘I am going to a journey, with a good heart and good courage’, Marguerite de Navarre, 1548). In Present Day French, courage is more of a resource, that can be lost or given, refilled or depleted, enabling one to act in face of a challenge or a peril. One can avoir le courage de Vinf (‘to have the courage to Vinf’), perdre courage (‘lose heart’), rassembler son courage (‘rally up one’s courage’), redonner du courage (‘to give one’s courage back’).
In this presentation, I want to emphasize the idea that the lexical meaning of a word is tied to the phraseological structures it enters to (Sinclair 1996, Paquot 2015). These phraseological patterns have received lately considerable scrutiny, especially thanks to corpus linguistics tools that allow these patterns to be automatically extracted (Kraif et al. 2025). Phraseological patterns can for instance be exploited to contrast close synonyms (e.g. persuader and convaincre, Gledhill 1995); here we rather contrast different historical stages of the use of a single lexeme (see Llavata 2024 for another phraseological approach to diachrony-related issues).
Practically, I first extract from the Frantext database (ATILF 1998-2026) the frequency profiles of a (qualitatively) selected set of phraseological uses of courage, accounting for the different spellings listed in the Dictionnaire du Moyen Français (DMF 2023). These phraseological uses have been selected based on a number of criteria: they are of a lexico-grammatical nature (they are not merely syntactic patterns and involve “fixed” elements), they must be recurrent enough in at least one time period, and they must be recoverable from a CQL query on the database. In total, they account for between 18% and 37% of all tokens, depending on the decade (27% on average). This is deemed satisfying, since a single lexeme is involved in a large variety of phraseological situations. For the time periods with a lesser coverage, I checked manually on random samples whether a lexico-grammatical pattern would recur, to make sure no major pattern had been left out. By detecting when the frequency shares of these patterns vary the most, I can pinpoint the semantic shift in the course of the 16th century, without relying on vector-based distributional representations of the meaning (Hu et al. 2019), laying the ground for an alternative empirical method to detect semantic shift.
Based on the phraseological patterns mentioned above, I identify a major semantic shift across the sixteenth century. This semantic shift is associated with a wide diversification of phraseological patterns (cf. Figure 1), and both the declining phrasemes (led by en mon courage) and the arising ones (dominated by avoir du courage) coexist at this time, while no phraseme accounts for the bulk of the token count. Moreover, the token frequency reaches a peak at that time. At the end of this transitional period, the new meaning, and its chief associated phraseological patterns, emerge in full. This example illustrates how essential the lexico-grammatical patterns are to understand the dynamics of change of a lexeme’s use.
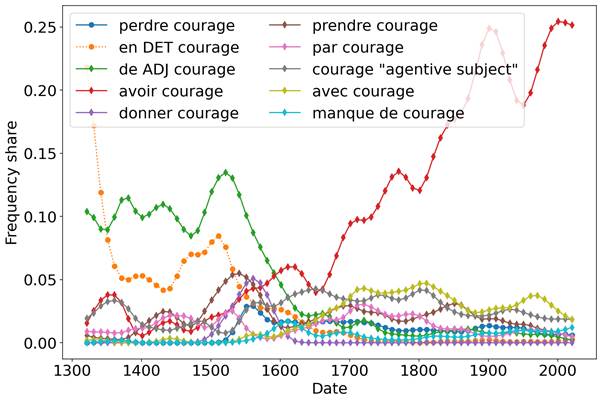
Figure 1: Frequency share among all uses of courage of a selected set of phraseological patterns
References
ATILF. Base textuelle Frantext (1998-2026). ATILF-CNRS & Université de Lorraine. https://www.frantext.fr/
DMF (2023). Dictionnaire du Moyen Français, version 2023. ATILF – CNRS & Université de Lorraine. Online website: http://www.atilf.fr/dmf
Gledhill, C. (1994). La Phraséologie et l’analyse des genres textuels. L’exemple des formules rhétoriques dans Le Monde. In Aston Papers in Language Studies and Discourse Analysis 2, Birmingham: Aston University.
Hu, R., Li, S., & Liang, S. (2019, July). Diachronic sense modeling with deep contextualized word embeddings: An ecological view. In Proceedings of the 57th annual meeting of the association for computational linguistics (pp. 3899-3908).
Kraif, O., Novakova, I., & Sorba, J. (2025). Périmètres des motifs phraséologiques: réflexion conceptuelle et méthodologique sur corpus littéraire contemporain. Corpus, 27.
Llavata, S. V. (2024). Desarrollos conceptuales en la expresión literaria del romancero nuevo: el amor y la milicia en sus formulaciones fraseológicas. Artifara, 24(2), 597-615.
Paquot, M. (2015). Lexicography and phraseology. In D. Biber & R. Reppen (eds), The Cambridge handbook of English corpus linguistics, Cambridge: Cambridge University Press (pp. 460-477).
Sinclair, J. (1996). The search for units of meaning. Textus, 9(1), 75-106.
Siouffi, G. (2012). Les binômes synonymiques et la question de la figure au XVIIe siècle: Quelques investigations dans l’usage et dans les remarques. In F. Berlan & G. Berthomieu (eds.), La synonymie, Paris: Presses de la Sorbonne (pp. 367-379).
Covarying Collexeme Analysis: A springboard for Usage-Based Constructional Instruction (UBICon)
Eleni KANLI & Evelyn WIESINGER
(Eberhard-Karls-University, Germany; University of Regensburg, Germany)
Traditional SLA research on multiword units has largely focused on lexical bundles or n-grams (see Hennecke et al., 2023), often relying on simple frequency measures, which may be distorting, particularly when n-grams contain highly frequent lexemes. By contrast, Construction Grammar conceptualizes conventionalized form-meaning pairings as constructions that range from fully lexicalized expressions to schematic patterns with open slots and span a continuum from lexical to grammatical meanings (Croft, 2001; Goldberg, 2006). Usage-based approaches posit that such constructions become cognitively entrenched through statistical learning, shaped by their distributional patterns in the input (Bybee, 2010) and by interactions with other variables (Guo & Pérez-Paredes, 2025). This contribution explores how theoretical concepts and inferential statistical methods from usage-based Construction Grammar can inform the identification of lexicogrammatical patterns for developing task-supported teaching units in Spanish as an additional language. It contributes to bridging the gap between corpus-based linguistic insights and classroom practice.
Collostructional analysis offers a nuanced, association-based approach to identifying co-occurring elements within constructions of varying schematicity (Gries, 2023). To date, it has been applied to SLA contexts only sparingly, and exclusively with a focus on English (Ellis & Ferreira-Junior, 2009a, 2009b; Ellis et al., 2016). For instance, studies have revealed differences in the association strength of English phrasal verbs between L1 and learner corpora (Deshors, 2016; Gilquin, 2015).
Our study applies covarying collexeme analysis (Stefanowitsch & Gries, 2005; Stefanowitsch & Flach, 2020; Flach, 2021) to Spanish [VERB PREP NOUN] constructions. However, rather than targeting a predefined construction type, we adopted an exploratory approach to uncover a range of constructions with statistically significant co-occurrences between lexical items in different slots. We identified constructions situated along a continuum between fixed lexical expressions (e.g. poner de relieve ‘to highlight’) and syntactic patterns (e.g. Vmotion de Nsource ‘to leave a location’), and others including a fixed element and an open slot (e.g. ir de Nevent, like ir de compras/fiesta/… ‘to go shopping/partying…’) using the esTenTen23 corpus in Sketchengine (Kanli & Wiesinger, in preparation). Subsequently, we analysed three first-year Spanish textbooks to identify which of these constructions are introduced at beginner level and how frequently students encounter them (Kanli, 2025; 2026).
We propose that such a data-driven identification of form-meaning pairs can serve as the basis for learning units, aligning with the principles of usage-based inspired L2-instruction (Tyler & Ortega, 2018), which advocate for form-function mappings in communicative instruction. These units integrate instructional approaches that raise learners’ awareness of target constructions in authentic communicative contexts, either explicitly or implicitly (e.g. Madlener & Behrens, 2022, p. 58), for example through colour highlighting or by manipulating the input flood in teaching material (e.g. Kanli, 2025; 2026).
To investigate whether this approach increases the accuracy and complexity of students’ written productions, we designed a 120-minute intervention called “Planning a weekend in a Spanish city” for fourteen-year-old Spanish learners at beginner level. Students discovered and used ‘directed motion constructions’, such as salir de casa (‘to leave one’s house’) (Talmy, 2000), as well as ‘activity/event constructions’, such as ir de fiesta (‘to go partying’). We tested the effectiveness of the intervention in a randomized controlled trial involving 269 plurilingual Spanish learners attending secondary schools (academic track) in Germany (Connolly et al., 2017; Kanli et al., 2025). Our talk will discuss the promising results of the cloze test (pre/post/delayed) and students’ written text productions (post/delayed), interpreting these results in the context of the previous covarying collexeme analysis of L1 data and the textbook analysis.
DeepL Write was used to support the linguistic revision of this abstract; all contents and interpretations remain the author’s responsibility.
References
Bybee, J. (2010). Language, Usage and Cognition. Cambridge University Press.
Connolly, P., Biggart, A., Miller, S., O’Hare, L., & Thurston, A. (2017). Using randomized controlled trials in education. SAGE.
Croft, W. (2001). Radical construction grammar: Syntactic theory in typological perspective. Oxford University Press.
Deshors, S. C. (2016). Inside phrasal verb constructions: A co-varying collexeme analysis of verb-particle combinations in EFL and their semantic associations. International Journal of Learner Corpus Research, 2(1), 1–30. https://doi.org/10.1075/ijlcr.2.1.01des
Ellis, N. C., Römer, U., & O’Donnell, M. B. (2016). Usage-based approaches to language acquisition and processing: Cognitive and corpus investigations of Construction Grammar. Wiley-Blackwell.
Ellis, N. C., & Ferreira-Junior, F. (2009a). Construction learning as a function of frequency, frequency distribution, and function. The Modern Language Journal, 93(3), 370–385. https://doi.org/10.1111/j.1540-4781.2009.00896.
Ellis, N. C., & Ferreira-Junior, F. (2009b). Constructions and their acquisition: Islands and the distinctiveness of their occupancy. Annual Review of Cognitive Linguistics, 7, 187–220. https://doi.org/10.1075/arcl.7.08ell
Flach, S. 2021. Collostructions: An R implementation for the family of collostructional methods. Package version v.0.2.0, https://sfla.ch/collostructions/.
Gilquin, G. (2015). The use of phrasal verbs by French-speaking EFL learners. A constructional and collostructional corpus-based approach. Corpus Linguistics and Linguistic Theory, 11(1). https://doi.org/10.1515/cllt-2014-0005
Goldberg, A. E. (2006). Constructions at work: The nature of generalization in language. Oxford University Press.
Gries, S. Th. (2023). Overhauling Collostructional Analysis: Towards More Descriptive Simplicity and More Explanatory Adequacy. Cognitive Semantics, 9(3), 351–386. https://doi.org/10.1163/23526416-bja10056
Guo, J. F., & Pérez-Paredes, P. (2025). The role of statistical learning in the L2 acquisition and use of nonadjacent predicate-argument constructions. Studies in Second Language Acquisition, 1–27. https://doi.org/10.1017/S0272263125101307
Hennecke, I., Perevozchikova, T., & Wiesinger, E. (2023). Multiword units in multilingual speakers. International Journal of Bilingualism, 0(0). https://doi.org/10.1177/13670069231200027
Kanli, E. (2025). Potentiale der Kognitiven Linguistik in der Fremdsprachendidaktik – Wie können wir Spanischlernende beim Erwerb der Konstruktion [ir + de/a + Nomen] unterstützen? In J. Kuhn, L. Becker, C. Ossenkop, C. Polzin-Haumann, & E. Prifti (Eds.), Kognitive Linguistik und Romanistik (pp. 187–214). Narr Francke Attempto Verlag.
Kanli, E. (2026). From input to interaction: A usage-based approach to teaching Spanish ser/estar + preposition + nominal phrase constructions at beginner level. International Journal of Bilingualism, 0(0). https://doi.org/10.1177/13670069251377428
Kanli, E., Wiesinger, E., Wolf, J., Meurers, D., Sering, K., Berens, F. (2025-05-06). Does the multilingual comparison of constructions facilitate learning? An analysis of the acquisition of the Spanish prepositions a and de after motion verbs through mono- and multilingual pedagogical construction grammar. Registry ID: #24080.1v1. Registry of Efficacy and Effectiveness Studies. The Society for Research on Educational Effectiveness. https://sreereg.icpsr.umich.edu/sreereg/subEntry/29122/pdf?section=all&action=download
Kanli, E. & Wiesinger, E. (in preparation). Why ir de compras ‘to go shopping’ is not trivial in Spanish. A synchronic and diachronic corpus analysis of motion verb + de ‘from, of’ + event noun constructions. Constructions.
Madlener-Charpentier, K., & Behrens, H. (2022). Konstruktion(en) erst- und zweitsprachlichen Wissens: Lernprozesse und Steuerungsoptionen aus gebrauchsbasierter Perspektive. In K. Madlener-Charpentier & G. Pagonis (Eds.), Aufmerksamkeitslenkung und Bewusstmachung in der Sprachvermittlung. Kognitive und didaktische Perspektiven auf Deutsch als Erst-, Zweit- und Fremdsprache (pp. 31–64). Narr Francke Attempto Verlag.
Stefanowitsch, A., & Gries, S. Th. (2005). Covarying collexemes. Corpus Linguistics and Linguistic Theory, 1(1), 1–43. https://doi.org/10.1515/cllt.2005.1.1.1
Stefanowitsch, A., & Flach, S. (2020). Too big to fail but big enough to pay for their mistakes: A collostructional analysis of the patterns [ too ADJ to V] and [ADJ enough to V]. In G. Corpas Pastor & J.-P. Colson (Eds.), IVITRA Research in Linguistics and Literature (pp. 247–272). John Benjamins Publishing Company. https://doi.org/10.1075/ivitra.24.13ste
Talmy, L. (2000). Toward a cognitive semantics: 1: Concept structuring systems: / Leonard Talmy; Vol. 1. The MIT Press.
Tyler, A. E., & Ortega, L. (2018). Chapter 1. Usage-inspired L2 instruction: An emergent, researched pedagogy. In A. E. Tyler, L. Ortega, M. Uno, & H. I. Park (Eds.), Language Learning & Language Teaching (pp. 3–26). John Benjamins. https://doi.org/10.1075/lllt.49.01tyl
Relayed futures and anticipated pasts: A corpus-based study of past-tense constructions with future reference in Swedish online discourse
Per KLANG
(Halmstad University, Sweden)
The past tense in Swedish is typically associated with reference to events preceding the moment of speech (Teleman et al. 1999; Larsson & Lyngfelt 2011). However, Swedish also exhibits systematic uses of the past tense where the temporal interpretation does not align with this expectation. Two such cases are the relayed future (Sw. Mötet var imorgon ‘The meeting was tomorrow’) and the anticipated past perspective (Sw. Berätta hur det gick imorgon ‘Tell me how it went tomorrow’) (Klang 2023). In the former, past tense signals that information about a future event was obtained in the past; in the latter, a speaker projects a future vantage point from which the event is seen as completed. Both constructions occur without modal auxiliaries and appear to challenge assumptions about the temporal interpretation of tense (Reichenbach 1947; Klein 1994).
Despite their theoretical interest, these constructions remain relatively understudied, likely because they are rare. Earlier work identified only thirty clear cases in a sample of more than sixty thousand Swedish past-tense forms (Klang 2023). A similarly low frequency has been reported for Dutch, where forty-one cases of past tense referring to future eventualities were found in a corpus of nearly 160,000 verb tokens (Haans & de Hoop 2023). Neither construction has been examined at scale with respect to its contextual distribution in Swedish.
The dataset comprises 5,000 instances of the Swedish past tense from an online discussion forum, including 1,000 instances each of the relayed future and the anticipated past perspective, and three comparison categories: (i) canonical past uses (events preceding the moment of speech), (ii) cases overlapping the moment of speech, and (iii) modal or counterfactual uses. The comparison data were drawn from a database of past and present tense use with deviant and non-deviant time reference (Klang 2023: 82).
Instances of the relayed future and the anticipated past perspective were collected through a three-stage corpus-based procedure using the corpus tool Korp (Borin et al. 2025), a filtering program, and manual assessment of approximately 10,000 candidates. All such instances contained the future time expression imorgon ‘tomorrow’, which served as a sampling criterion to ensure lexical control over future reference.
The study treats these constructions as a case of context-dependent ambiguity, where the same past-tense form may correspond to different temporal interpretations depending on context. Contextual word embeddings were extracted using the Swedish transformer model KB-BERT (Malmsten et al. 2020). A probing classifier was then used to test whether the tense interpretations can be distinguished on the basis of contextual embeddings. The classifier achieves accuracy well above chance level (0.872), indicating that the constructions occur in systematically different contextual environments. Masking experiments on the past-tense verb and imorgon ‘tomorrow’, together with complementary lexical and grammatical analyses, further show that contextual cues remain highly informative even when overt tense-related material is reduced.
The results suggest that temporal interpretation in Swedish may be shaped not only by tense morphology and overt temporal markers but also largely by recurrent lexicogrammatical patterns in the surrounding context. This provides empirical support for the view that the interaction of lexical context and grammatical tense marking plays a central role in temporal interpretation.
References
Borin, Lars, Forsberg, Markus, Hammarstedt, Martin, Holmer, Louise & Matsson, Arild. 2025. Korp: Språkbanken’s word research platform. In: Dana Dannélls, Kristian Blensenius & Lars Borin (eds.) Sixty years of Swedish computational lexicography. De Gruyter.
Malmsten, Martin, Börjeson, Love & Haffenden, Chris. 2020. Playing with words at the National Library of Sweden: Making a Swedish BERT. arXiv preprint arXiv:2007.01658.
Haans, Harvey & de Hoop, Helen. 2023. Past tense reference to future eventualities: A Reichenbachian approach. Linguistics in the Netherlands, 40(1), 55–68.
Klang, Per. 2023. Incongruous tense in Swedish: Past and present tense use with deviant time reference. Dissertation, Acta Universitatis Upsaliensis.
Klein, Wolfgang. 1994. Time in Language. London: Routledge.
Larsson, Ida & Lyngfelt, Benjamin. 2011. Tempus i svenskan. In: Christiane Andersen, Antoaneta Granberg & Ingmar Söhrman (eds.) Tid och tidsförhållanden i olika språk. (Studia Interdisciplinaria, Linguistica et Litteraria (SILL) 2.) Gothenburg: Department of language and literature, Gothenburg University. 66–88.
Reichenbach, Hans. 1947. Elements of Symbolic Logic. New York: Dover Publications Inc.
Teleman, Ulf, Hellberg, Staffan & Andersson, Erik. 1999: Svenska Akademiens Grammatik. Volume 4. Stockholm: The Swedish Academy.
Influence of Animacy and Collectivity on the Production of the Optional Mandarin Plural Marker men
Pu MENG
(George Mason University, USA)
The Mandarin marker men is traditionally described as an optional plural or collective marker restricted to human nouns (Li 1999; Iljic 1994). However, recent corpus-based studies of spoken Mandarin suggest that men is more flexible, occasionally appearing with non-human nouns and extending beyond strict plurality (e.g., diminutive or pragmatic uses; Cook 2009, 2019; Cook & Yao 2025). At the same time, plural reference in Mandarin is frequently expressed through quantifier–classifier constructions (Kim 2008; Kim & Meng 2022), raising questions about how men interacts with alternative lexicogrammatical strategies in naturalistic usage.
While corpus methods provide rich evidence of attested uses of men, they offer limited access to contexts where men could have been used but was omitted. To address this gap, the current study adopts an experimental production approach designed to complement corpus findings by systematically manipulating discourse conditions that are difficult to isolate in naturalistic data. In doing so, the study bridges corpus-observed patterns with controlled evidence on speakers’ choices among competing number-marking strategies.
Native speakers of Mandarin (n = 84) completed a picture description task. Stimuli varied by animacy (human, animal, object) and number/collectivity (singular, plural-individual, plural-group). Participants’ descriptions were audio-recorded and coded for the presence of men and other number-marking strategies, including quantifier–classifier expressions (e.g., ji ge “several”), singular forms (e.g., yi ge “one”), and unmarked nouns. This design allows us to approximate distributional contrasts observed in corpus data while explicitly testing factors hypothesized to underlie those patterns.
Results show a strong effect of animacy and number, but no reliable effect of collectivity (Figures 1 and 2). The marker men occurred in approximately 60% of human plural contexts and 36% of animal plural contexts, but was absent in singular contexts and rare with object plurals. Mixed-effects models confirmed significant effects of animacy contrasts (human vs. nonhuman; animal vs. object; ps < .001), with no significant effects of collectivity or interactions (ps > .5). Importantly, plural-individual and plural-group conditions showed similar distributions not only for men, but also for alternative plural-marking strategies, suggesting that speakers’ choices are not strongly conditioned by group coherence.
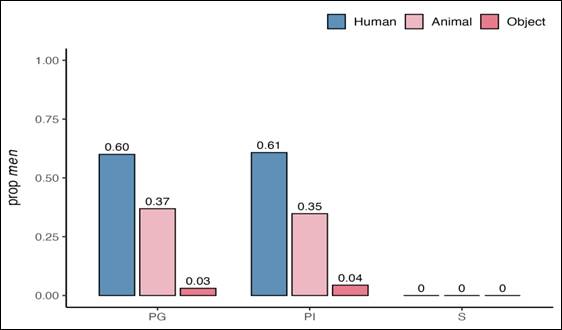
Figure 1. Proportion of nouns marked with men across different animacy categories (human, animal, inanimate) and number conditions (singular, plural individual, plural group).
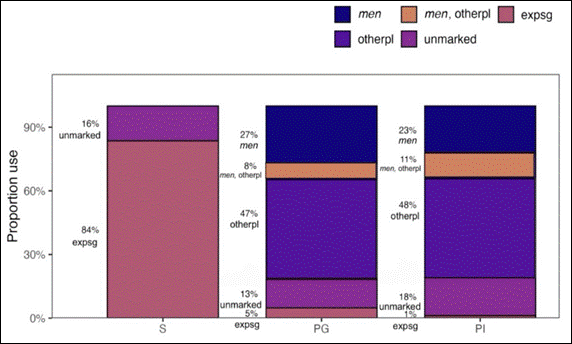
Figure 2. Distribution of number-marking strategies (men, men with other plural expression, other plural expression, singular expression, unmarked) across different number conditions (singular, plural individual, plural group).
These findings align with corpus observations that men is not categorically restricted to human referents and highlight the role of animacy and number as primary constraints on its distribution. By providing controlled evidence on both the use and non-use of men, the study contributes to a more complete account of Mandarin plural marking and clarifies how lexicogrammatical variation observed in corpora may arise from underlying production preferences. More broadly, the results illustrate how experimental data can inform corpus-based research by identifying probabilistic tendencies and gaps in attested distributions, with implications for future corpus annotation and diachronic analysis.
References
Cook, A. (2009). Why should men break all the rules? A new approach to analyzing the plural marker men in Mandarin Chinese. Linguistics & the Human Sciences, 5(2).
Cook, A. (2019). Constraints on the use of the plural morpheme men in spoken Mandarin. Lingua Sinica, 5(1), 30-57.
Cook, A., & Yao, D. (2025). Who says men can never change? A corpus-based study of recent changes in the use of the Chinese plural suffix men. Australian Review of Applied Linguistics.
Iljic, R. (1994). Quantification in Mandarin Chinese: Two markers of plurality.
Kim, J. (2008). The parameterization of plural markings in classifier languages. Kansas Working Papers in Linguistics, 30, 159–173.
Kim, K., & Meng, X. (2022). Variation in the syntax of plural markers: The case of plural–men in Mandarin. Studia Linguistica, 76(2), 507-551.
Li, Y. H. A. (1999). Plurality in a classifier language. Journal of East Asian Linguistics, 8, 75–99.
A corpus-based approach to lexically-constrained usage patterns of determiners in L2 Spanish oral production
Sarah RUBIO & Sara L. ZAHLER
(Binghamton University, USA; North Carolina State University, USA)
Despite similarities in the determiner paradigms in both languages, English-speaking L2 Spanish learners often demonstrate determiner usage that differs from Spanish-dominant speakers. Learner interlanguage patterns are frequently attributed to cross-linguistic differences in mappings between determiner forms and semantic functions such as specificity, definiteness, and genericity, particularly for indefinite (un/una ‘a/an’) and definite articles (el/la ‘the’). These learner-specific patterns are documented using production, interpretation, and acceptability tasks, even at advanced levels, especially with the generic use of the definite article in Spanish (e.g., Cuza et al., 2012; Ionin et al., 2010; Miller, 2020; Montrul & Ionin, 2012).
Usage-based approaches to L2 acquisition postulate that beyond L1 influence, cue availability and reliability impact development (Bybee, 2008; Ellis & Wulff, 2020). Studies on other language pairings show that the frequency of determiner-function pairings in the input (cue availability) and how often said function predicts the use of a specific determiner (cue reliability) do modulate L2 determiner use (e.g., Romain et al., 2024; Zhao & Fan, 2021). However, to our knowledge, researchers have yet to analyze the effects on determiner acquisition of noun frequency, determiner-noun collocation frequency, and determiner-noun association.
Accordingly, we adopt a usage-based approach, arguing that definite article production in advanced L2 Spanish learners is impacted by lexically-specific input patterns. Using oral data from 11 advanced L1 English-L2 Spanish learners, we investigated the rate of definite article (el/la ‘the’) use compared to all other determiners (total k = 1661). We analyzed the impact of syntactic, semantic, pragmatic, and usage-based factors, including specificity, definiteness, genericity, animacy, countability, syntactic function, and NP structure. Each token was also coded for noun frequency, determiner-noun collocational frequency, and determiner-noun association derived from CORPES (Real Academia Española).
Mixed-effects binomial regression analyses revealed higher definite article production in specific, definite, generic, and non-animate contexts. The definite article was also more frequent with temporal adjuncts and prepositional objects, and with singular nouns and those with postnominal modifiers. Importantly, noun frequency, determiner-noun collocation frequency, and determiner-noun association significantly impacted definite article production as expected. A conditional inference tree showed that the first and most important split was determiner-noun association, separating nouns more strongly associated with the definite article from those less so, with subsequent splits reflecting interactions among semantic, syntactic, and lexically-specific frequency variables. Cumulative usage of the noun with the definite article along with higher cue availability and reliability led to higher definite article use where expected in Spanish, but not English (generic reference), mediating cross-linguistic influence.
These findings align with usage-based and lexicogrammatical approaches. Specifically, determiner-noun association was a highly reliable cue linking form (definite article) to recurring lexically-anchored patterns. These results suggest that advanced L2 learners’ determiner systems are shaped by interactions between semantic-pragmatic constraints and lexically-grounded distributional learning, supporting a model in which grammatical development proceeds from item-based patterns toward increasingly abstract, yet probabilistically constrained, representations.
References
Bybee, J. (2008). Usage-based grammar and second language acquisition. In P. Robinson & N.C. Ellis (Eds.), Handbook of cognitive linguistics and second language acquisition (pp. 216-236). New York: Routledge. https://doi.org/10.4324/9780203938560
Cuza, A., Guijarro-Fuentes, P., Pires, A., & Rothman, J. (2012). The syntax-semantics of bare and definite plural subjects in the L2 Spanish of English natives. International Journal of Bilingualism, 17(5), 634-652. https://doi.org/10.1177/1367006911435594
Ellis, N.C., & Wulff, S. (2020). Usage-based approaches to L2 acquisition. In B. VanPatten, G. D: Keating & S. Wulff (Eds.), Theories in second language acquisition: An introduction (pp. 63-82). New York: Routledge. https://doi.org/10.4324/9780429503986
Ionin, T., Montrul, S., & Crivos, M. (2010). A bidirectional study on the acquisition of plural noun phrase interpretation in English and Spanish. Applied Psycholinguistics, 34(3), 483-518. https://doi.org/10.1017/S0142716411000841
Miller, L. (2020). When bilinguals outperform monolinguals: Evidence from definite and bare noun phrases in Spanish and English. Revista Española de Lingüística, 33(2), 475-504. https://doi.org/10.1075/resla.18003.mil
Montrul, S., & Ionin, T. (2012). Dominant language transfer in Spanish heritage speakers and second language learners in the interpretation of definite articles. The Modern Language Journal, 96(1), 70-94. https://doi.org/10.1111/j.1540-4781.2012.01278.x
Real Academia Española: Banco de datos (CORPES XXI) [en línea]. Corpus del Español del Siglo XXI (CORPES). http://www.rae.es [March 19, 2026].
Romain, L., Milin, P., & Divjak, D. (2024). Order effects in second language learning. Language Learning, 75(3), 623-665. https://doi.org/10.1111/lang.12675
Zhao, H., & Fan, J. (2021). Modeling input factors in second language acquisition of the English article construction. Frontiers in Psychology, 12, Article 653258. https://doi.org/10.3389/fpsyg.2021.653258
Experiential spiritual knowledge and the construal of epistemic authority in digital contemplative influencer discourse
Margo VAN POUCKE
(Macquarie University, Australia)
Digital religious communication has encouraged a form of influencer discourse in which authority appears through continuous interaction with dispersed audiences under conditions of public visibility and audience response (Campbell, 2007, 2010; Campbell & Bellar, 2022; Cheong, 2016; Van Poucke, 2025). This study seeks to understand how epistemic authority is achieved lexicogrammatically in religious influencer discourse on YouTube which promotes spiritual formation, contemplative practice and experiential discernment as belief systems (Bartsch et al., 2025). Epistemic authority is regarded as a discursive effect arising from the regulation of epistemic commitment, the invocation of shared assumptions and the fine-tuning of interpersonal force, realised through recurrent tenor resources, commonly described as stance constructions in corpus linguistics. In the study, religious authority refers to socially recognised standing in a faith tradition, whereas epistemic authority concerns the discursive presentation of knowledge and credibility.
Adopting a corpus-assisted discourse studies (CADS) approach, the analysis combines association-based keyness, dispersion measures and qualitative concordance-based appraisal analysis. Interpersonal meaning is interpreted through the tenor system and its dimensions of positioning, orienting and tuning (Doran et al., 2026; Martin & White, 2005). For the purpose of quantitative analysis, stance is operationalised through (semi)modal verbs (may, be going to), modal adjuncts (maybe, perhaps) and mental verb projections (think, believe), which are viewed as lexicogrammatical resources for positioning, orienting and tuning that regulate epistemic commitment and audience alignment. The study aims to answer the following questions:
- How are the interpersonal resources distributed in multiple transcripts included in the corpus?
- How can widely distributed constructions be differentiated from localised patterns?
- How do salient tenor configurations contribute to the construal of epistemic authority in digitally mediated discourse shared by contemplative influencers?
The dataset comprises 4,065 transcripts of English-language YouTube videos, uploaded between 2010 and 2025 and totalling approximately 11 million words. The transcripts represent a form of religious influencer discourse, in which a general audience is addressed in a shared domain of spiritual formation (Rundin & Colliander, 2021; Sheldon, 2024). This corpus is contrasted with a reference corpus of 190 sermons delivered by preachers to internal audiences during the same time period, hosted on SermonAudio, providing a baseline that is representative of formally sanctioned religious authority. The comparison is specific to the register and designed to isolate resources connected to authority in the same discourse domain.
Keyness, understood as relative prevalence in comparison with the reference corpus, is calculated using Kullback-Leibler (KL) divergence, which is applied to a predefined inventory of interpersonal constructions, while dispersion metrics differentiate between widely distributed features and those concentrated in specific stretches (Gries, 2024). Concordance analysis is used to explore how the distributions are linked to recurring passages of guidance and directive emphasis.
The findings show a stratified distribution of interpersonal resources. Widely dispersed forms, including mental verb projections, such as I think or I find, and modals of possibility, such as can or could, establish a background pattern of epistemic openness, which is based on personal experience. More narrowly dispersed items, including (semi)modals of obligation, such as be supposed to, have to or (have) got to, cluster in key passages tied to intensified guidance and viewer alignment. These distributional contrasts may be mapped onto shifts in tenor. Positioning presents speakers as reflective participants and mentors. Orienting invokes collective commitment to spiritual practices. Tuning adjusts interpersonal force through modulation in the Hallidayan sense by alternating phases of openness and strong instruction. Epistemic authority in this type of discourse results from patterned modulation of salient tenor resources. Speakers maintain emotional proximity and credibility while steering interpretation and practice in a communicative setting in which institutional endorsement is backgrounded. The analysis links distributional evidence derived from corpus methods to Appraisal theory to describe the lexicogrammatical realisation of authority in digitally mediated religious discourse, clarifying how persuasive influence is exerted in platform economies that are affected by audience engagement and monetisation.
References
Bartsch, A., Neuberger, C., Stark, B., Karnowski, V., Maurer, M., Pentzold, C., Quandt, T., Quiring, O., & Schemer, C. (2025). Epistemic authority in the digital public sphere: An integrative conceptual framework and research agenda, Communication Theory, 35(1), 37–50. https://doi.org/10.1093/ct/qtae020
Campbell, H. A. (2007). Who’s got the power? Religious authority and the Internet. Journal of Computer-Mediated Communication, 12(3), 1043–1062. https://doi.org/10.1111/j.1083- 6101.2007.00362.x
Campbell, H. A. (2010). Religious authority and the blogosphere. Journal of Computer-Mediated Communication, 15(2), 251–276.
Campbell, H. A., & Bellar, W. (2022). Digital religion: The basics. Routledge.
Cheong, P. H. (2016). Religious authority and social media branding in a culture of religious celebrification. In S. M. Hoover (ed.), The media and religious authority (pp. 81–102). Penn State University Press. https://doi.org/10.1515/9780271077956
Doran, Y. J., Martin, J. R., & Zappavigna, M. (2026). Negotiating social relations: Tenor resources in English. University of Toronto Press.
Gries, S. Th. (2024). Frequency, dispersion, association, and keyness: Revising and tupleizing corpus-linguistic measures. John Benjamins Publishing Company.
Martin, J., & White, P. R. R. (2005). The language of evaluation: Appraisal in English. Palgrave Macmillan.
Rundin, K., & Colliander, J. (2021). Multifaceted influencers: Toward a new typology for influencer roles in advertising. Journal of Advertising, 50(5), 548–564. https://doi.org/10.1080/00913367.2021.1980471
Sheldon, Z. (2024). Christian influence: The subcultural narratives of Evangelical celebrities on Instagram. Taylor & Francis.
Van Poucke, M. (2025). Negotiating the maze of menopause misinformation: A comparative analysis of stance in health influencer versus medical professional discourse. Atlantic Journal of Communication, 1–23. https://doi.org/10.1080/15456870.2025.2453738
Disentangling the Construct of Phraseological Sophistication: A Validation Study with Human Judgments
Gabriela VAUGHAN & Magali PAQUOT
(UCLouvain, Belgium)
Linguistic complexity is regarded as a major research variable in Applied Linguistics (AL), being used to describe L2 performance, assess L2 proficiency, and trace L2 development (Housen & Kuiken, 2009; Paquot, 2019). Existing research on complexity has largely focused on developing measures of lexical and syntactic complexity (Bulté & Housen, 2012), neglecting those at the lexis-grammar interface. At the same time, phraseology has widely been recognised as playing an important role in language proficiency and development (Wray, 2002). Learner Corpus Research has established that more proficient second language learners (L2) use a wider range of collocations and more sophisticated recurrent word combinations than less proficient learners (Bestgen & Granger, 2018; Paquot, 2019). Despite this, there remains a lack of studies which theorise and operationalise linguistic complexity at this interface in phrasal-level language production.
To address this gap, Paquot (2019) proposed the construct of phraseological complexity, defined by both range (diversity) and sophistication. According to this conceptualisation, a learner’s text is considered more complex when it contains a higher proportion of sophisticated, varied (diversity) phraseological units rather than frequent repetitions of common word combinations (Paquot, 2019). Automated corpus-based measures of phraseological sophistication are particularly promising linguistic measures for distinguishing among proficiency levels (CEFR) (Paquot, 2019; Vandeweerd et al., 2021; Jiang et al., 2021). However, the construct validity of these measures has not been adequately addressed, as it remains unclear to what extent they align with human perceptions of phraseological sophistication (and complexity). From a validity-argument perspective, this constitutes a significant gap in learner corpus research, as a linguistic construct must reflect a perceptual reality to be valid, which can only be achieved by capturing human perception of the targeted construct (Jarvis, 2017).
This work-in-progress study addresses this issue by gathering data on the human perception of phraseological sophistication in collocations. Phraseological sophistication is theorised to be measured across three dimensions: register specificity, association strength, and frequency (Paquot & Naets, 2025). A set of 120 verb–object collocations was extracted from a Wikicorpus and balanced across these dimensions using corpus-based measures. Thirty expert judges evaluated these collocations using a comparative judgment task (Thwaites & Paquot, 2024). Comparative judgment is a novel approach that has proven useful for evaluating complex linguistic constructs (Crossley et al., 2023; Zhang & Lu, 2024). This study aims (1) to determine the extent to which L1 English speakers share intuitions about phraseological sophistication, (2) to determine the influence of register specificity, association strength, and frequency on those intuitions, and (3) to establish the construct validity of this corpus-based measure. Drawing on L2 phraseological research, we expect that judges will rank collocations that are register-specific, strongly associated, and relatively uncommon as more sophisticated. Analysis will employ Scale Separation Reliability and infit statistics to determine whether judges share intuitions regarding phraseological sophistication (Pollitt, 2012). Regression modelling will be used to investigate which dimensions of phraseological sophistication most predict human judgments. The task will also require judges to provide comments regarding their decision-making process, enabling a qualitative analysis of what guided their decision-making.
This Comparative Judgment task will be conducted in Spring 2026 using the No More Marking platform, and this presentation will report the first results from the study. By integrating human perception data with automatic corpus-based measures, this project aims to enhance our theoretical and methodological understanding of phraseological complexity and clarify its role in Second Language Acquisition research.
References
Bestgen, Y., & Granger, S. (2018). Tracking L2 writers’ phraseological development using collgrams: Evidence from a longitudinal EFL corpus. In S. Hoffman & A. Sand (Eds.), Corpora and lexis (pp. 277–301). Brill.
Bulté, B., & Housen, A. (2012) Defining and operationalising L2 complexity. In: Housen A, Kuiken F, and Vedder I (eds) Dimensions of L2 performance and proficiency: Complexity, accuracy and fluency in SLA. Amsterdam: Benjamins, pp. 21–46
Crossley, S. A., Salsbury, T., McNamara, D. S., & Jarvis, S. (2011). Predicting lexical proficiency in language learner texts using computational indices. Language Testing, 28(4), 561–580. https://doi.org/10.1177/0265532210378031
Housen, A., & Kuiken, F. (2009). Complexity, Accuracy, and Fluency in Second Language Acquisition. Applied Linguistics, 30(4), 461–473. https://doi.org/10.1093/applin/amp048
Jiang, J., Bi, P., Xie, N., & Liu, H. (2021). Phraseological complexity and low- and intermediate-level L2 learners’ writing quality. International Review of Applied Linguistics in Language Teaching, 61(3), 765–790. https://doi.org/10.1515/iral-2019-0147
Paquot, M. (2019). The phraseological dimension in interlanguage complexity research. Second Language Research, 35(1), 121–145. https://doi.org/10.1177/0267658317694221
Paquot, M., & Naets, H. (2024). Phraseological sophistication as a multidimensional construct: Exploring the relationship between association, register specificity and frequency. International Journal of Learner Corpus Research, 11, forth.
Pollitt, A. (2012). The method of Adaptive Comparative Judgement. Assessment in Education: Principles, Policy & Practice, 19(3), 281–300. https://doi.org/10.1080/0969594X.2012.665354
Thwaites, P., & Paquot, M. (2024). Comparative judgement for advancing research in applied linguistics. Research Methods in Applied Linguistics, 3(3), 100142. https://doi.org/10.1016/j.rmal.2024.100142
Vandeweerd, N., Housen, A., & Paquot, M. (2021). Applying phraseological complexity measures to L2 French: A partial replication study. International Journal of Learner Corpus Research, 7(2), 197–229.
Zhang, X., & Lu, X. (2024). Testing the Relationship of Linguistic Complexity to Second Language Learners’ Comparative Judgment on Text Difficulty. Language Learning, 74(3), 672–706. https://doi.org/10.1111/lang.12633
Measuring diachronic change in conversion: A comparison of surprisal-based metrics
Gui WANG
(Zhejiang University, China)
Conversion, in which a word shifts between grammatical categories without morphological marking (Plag, 2003) (e.g., noun access → verb to access), offers a productive test case for corpus-based lexico-grammatical research. Tracking how such shifts become conventionalized requires measures sensitive to both lexical entrenchment and syntactic category conventionalization, two dimensions that may follow distinct trajectories over time. Surprisal, the negative log-probability of a linguistic unit given its context (Hale, 2001; Levy, 2008), quantifies how unexpected a form is in a given context: a word occurring in a highly predictable environment receives low surprisal, while one appearing in an unexpected context receives high surprisal. As a word form becomes more entrenched in a given grammatical category, its occurrence in that category should become increasingly predictable and thus associated with lower surprisal. For instance, a noun that has been frequently reused as a verb should attract lower syntactic surprisal in verbal positions over time. Surprisal has been widely used in psycholinguistics as a quantitative index of processing cost and entrenchment (e.g., Fernandez Monsalve et al., 2012; Futrell & Levy, 2017; Staub, 2025), but its application to corpus-based lexicogrammatical research remains limited. This study therefore asks: do different surprisal-based metrics capture distinct dimensions of diachronic change in conversion, and if so, what are the implications for operationalizing entrenchment at the lexical and grammatical levels?
This paper compares three surprisal-based metrics in a diachronic corpus study of conversion in English. Conversion words were identified via zero-derivation morphology in the CELEX lexical database (Baayen et al., 1995) and retained based on frequency thresholds in COHA (Corpus of Contemporary American English; Davies, 2010). Specifically, the base form was required to appear at least 50 times per decade, and the converted form at least 100 times in total across at least 8 of the 10 decades. The asymmetric thresholds reflect the typically lower frequency of converted forms, ensuring sufficient temporal coverage without selection bias. This yields 639 noun-to-verb (N2V) and 443 verb-to-noun (V2N) conversion words from COHA (1920s–2010s). Conversion degree, defined as the proportion of converted-form use out of total lemma use, serves as the dependent variable, operationalizing entrenchment as the degree to which a word has become conventionalized in its converted category over time. We compare three surprisal-based metrics as predictors: (1) local 5-gram surprisal, as a proxy for lexical entrenchment in surface sequential patterns; (2) GPT-2 surprisal, capturing contextual semantic expectation over broad left-context; and (3) POS-gram surprisal, reflecting syntactic category conventionalization. Grounded in the view that lexis and grammar form an integrated continuum, we follow Roark et al. (2009) and van Schijndel et al. (2015) in separating lexical and syntactic surprisal, extending this decomposition to the domain of word formation and diachronic change.
Pearson correlation analyses on decade-standardized values reveal selective overlap across both conversion directions. Local 5-gram and GPT-2 surprisal show moderate positive correlations (N2V: r = .20; V2N: r = .43; both p < .001), suggesting they capture related but non-redundant aspects of lexical probability. POS-gram surprisal, by contrast, shows consistently weak correlations with both lexical measures (|r| ≤ .16), supporting its status as an empirically distinct predictor tracking grammatical rather than lexical conventionalization. Generalized linear mixed-effects models (GLMMs) further confirm that all three metrics contribute non-overlapping variance in predicting diachronic conversion degree for both N2V and V2N patterns.
These results argue against treating surprisal metrics as interchangeable operationalizations of a single construct. For corpus-based lexicogrammar research, the choice of metric is not methodologically neutral: relying solely on surface n-gram models risks underestimating broader semantic context, while collapsing lexical and syntactic surprisal obscures an empirically real asymmetry between these two dimensions of entrenchment. We discuss implications for the selection and interpretation of surprisal-based metrics in corpus studies targeting the lexis–grammar interface, and consider what the differential behavior of these metrics reveals about the mechanisms of diachronic change in conversion.
References
Baayen, H., Piepenbrock, R., & Gulikers, L. (1995). CELEX2 (p. 287744 KB) [Dataset]. Linguistic Data Consortium. https://doi.org/10.35111/GS6S-GM48
Davies, M. (2010). The Corpus of Historical American English (COHA) [Dataset]. https://www.english-corpora.org/coha/
Fernandez Monsalve, I., Frank, S. L., & Vigliocco, G. (2012). Lexical surprisal as a general predictor of reading time. In W. Daelemans (Ed.), Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics (pp. 398–408). Association for Computational Linguistics. https://aclanthology.org/E12-1041/
Futrell, R., & Levy, R. (2017). Noisy-context surprisal as a human sentence processing cost model. In M. Lapata, P. Blunsom, & A. Koller (Eds.), Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers (pp. 688–698). Association for Computational Linguistics. https://aclanthology.org/E17-1065/
Hale, J. (2001). A probabilistic earley parser as a psycholinguistic model. Second Meeting of the North American Chapter of the Association for Computational Linguistics on Language Technologies 2001 – NAACL, 1–8. https://doi.org/10.3115/1073336.1073357
Levy, R. (2008). Expectation-based syntactic comprehension. Cognition, 106(3), 1126–1177. https://doi.org/10.1016/j.cognition.2007.05.006
Plag, I. (2003). Word-formation in English. Cambridge University Press.
Roark, B., Bachrach, A., Cardenas, C., & Pallier, C. (2009). Deriving lexical and syntactic expectation-based measures for psycholinguistic modeling via incremental top-down parsing. In P. Koehn & R. Mihalcea (Eds.), Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing (pp. 324–333). Association for Computational Linguistics. https://aclanthology.org/D09-1034/
Staub, A. (2025). Predictability in Language Comprehension: Prospects and Problems for Surprisal. Annual Review of Linguistics, 11(1), 17–34. https://doi.org/10.1146/annurev-linguistics-011724-121517
van Schijndel, M., Murphy, B., & Schuler, W. (2015). Evidence of syntactic working memory usage in MEG data. In T. O’Donnell & M. van Schijndel (Eds.), Proceedings of the 6th Workshop on Cognitive Modeling and Computational Linguistics (pp. 79–88). Association for Computational Linguistics. https://doi.org/10.3115/v1/W15-1109
The TAME Multifunctionality of the Chinese Particle LE from the Perspective of English Correspondences: A Grounding Approach
Yina WANG & Xiaoran LI
(Beihang University, China)
The complex uses of the Chinese particle LE have long been a focal point in linguistic studies. Previous investigations have provided detailed descriptions of its types (Zhu, 1982; Liu, 1990; Shen, 2021; Jing-Schmidt et al., 2022; Lu & Zhu, 2025), its capacity to form complete sentences (Shen, 1995; Wang & Huang, 2020; Liu et al., 2023), and the functions it expresses (Li & Thompson, 1981; Chu, 2013; Lin, 2017; Fan, 2024). Substantial progress has been made in these areas, however, there is still no consensus on these three dimensions. Moreover, existing studies have paid insufficient attention to cross-linguistic perspectives and have rarely employed quantitative methods.
The present study adopts grounding theory (Langacker, 2008) to examine the multifunctionality of LE in authentic discourse. Within this framework, grounding refers to the process by which a profiled event is related to the ground, thereby anchoring discourse reality and completing sentences. Against this backdrop, the study addresses three questions:
- What functions of LE can be identified through its English correspondences, and what are their respective frequencies?
- How are these functions conditioned by morphosyntactic and semantic variables?
- What grounding properties of LE emerge from these functional patterns?
The analysis draws on a self-built Chinese-English Literary Parallel Corpus (CELPC), consisting of ten Chinese original literary texts and their corresponding English translations by professional translators.[1] Using CUC_Paraconc, all sentence pairs containing LE and their English correspondences were extracted. From these, 1,000 occurrences were randomly selected for detailed annotation and analysis. The dependent variable was the functions of LE identified through its English correspondences.[2] Independent variables included the position of LE, subject type, verb type, verb-complement type, serial-verb relation, sentence type, polarity, presence of temporal words, and presence of modal words. The study adopts a multivariate analysis, i.e. Conditional Inference Trees (CIT), to model the variables contributing to functional interpretation of LE. The CIT algorithm recursively selects the most statistically significant predictor at each node, producing a hierarchical structure of conditions that explain functional variation in LE.
The findings are threefold. First, the English correspondences of LE reveal aspectual (28.89%), temporal (57.78%), modal (3.84%), and evidential (3%) meanings, demonstrating that it displays a continuum of grounding functions across the TAME (Tense-Aspect-Modality-Evidentiality) stratum. Second, CIT modeling shows that, the multifunctionality of LE is constrained by a hierarchy of variables: verb type > sentence type > serial-verb construction > verb-complement type > position of LE > subject type > presence of modal words > presence of temporal words> polarity. Third, LE displays both descriptive and interactive grounding properties, with the speaker or the speaker-addressee interaction at speech moment serving as the grounding anchor. In sum, the particle LE assumes both descriptive and interactive functions, and its multifunctional unity reflects the subject-object integration of Chinese.
These findings support a unitary account of LE as a multifunctional grounding element whose descriptive and interactive functions jointly contribute to sentence completion in Mandarin. More broadly, the study illustrates how parallel corpus evidence and multivariate modeling can advance usage-based explanations of grammatical multifunctionality.
References
Chu, C. C. (2013). From grammatical research to grammar teaching — A case study of the Modern Chinese perfective marker “le₁”. In Y. Shen (Ed.), Modern Chinese Grammatical Research Moving Toward Contemporary Science. Beijing: The Commercial Press.
Fan, X. L. (2024). The methodology of analyzing the particle le. Contemporary Linguistics, 26(1): 116-138.
Jing-Schmidt, Z., Lang, J., Shi, H. H., Hung, S. H., & Zhu, L. (2022). Aspect construal in mandarin: a usage-based constructionist perspective on LE. Linguistics, 60(2), 541-577.
Langacker, R. W. (2008). Cognitive grammar. A basic introduction. Oxford University Press.
Li, C. N., & Thompson, S. A. (1981). Mandarin Chinese. A functional reference grammar. California: University of California Press.
Lin, R. W. (2017). The temporal meaning of the verbal-le revisited. Studies of the Chinese Language, (1): 3-21+126.
Liu, X. N. (1990). The grammatical meaning of sentence-final le in Modern Chinese and Its Relation to the Suffix le. Chinese Teaching in the World, (2): 80-87.
Liu, Z. G., Shi, Z. Y., & Zhang, Z. Y. (2023). Construal, temporal dimensionality and the tense-aspect-modality multifunctionality of Le. Journal of Foreign Languages, 46(6): 45-56.
Lu, F. Z., & Zhu, B. (2025). Reinvestigation into the meaning of “change” expressed by the auxiliary particle Le in modern Chinese. Chinese Linguistics, (1): 49-59.
Shen, J. X. (1995). Boundedness and unboundedness. Studies of the Chinese Language, (5): 367-380.
Shen, J. X. (2021). Nominal TAM marking: Challenge and response, with special reference to the particle le in Chinese. Contemporary Linguistics, 23(4): 475-507.
Wang, J., & Huang, M. D. (2020). The influencing factors of the sentence-formation ability of “le1” and “le2”. Chinese Language Learning, (1): 3-13.
Zhu, D. X. (1982). Notes of grammar. Beijing: The Commercial Press.
Endnotes
[1] This corpus was jointly developed by the doctoral and master’s research team led by Professor Wang Yina. The ten works included are: Half a Lifelong Romance, Folding Beijing, The Teahouse, My Memories of Old Beijing, Big Breasts and Wide Hips, Thunderstorm, Passage, Rickshaw Boy, The Three-Body Problem, and Fortress Besieged. All translations are published literary translations intended for general readership.
[2] Examples for the identification of LE functions are provided in the Appendix.
How the grammar of reduplication changes lexis in Mandarin Chinese: A distributional semantics investigation
Chaoyi WU & R. Harald BAAYEN
(Beihang University, China; Eberhard Karls University, Germany)
Mandarin Chinese has two reduplicative constructions that repeat the constituents of two-character compounds in two possible ways. One construction (henceforth AABB) reduplicates the first constituent and then the second constituent, as in 健健康康 jian4-jian4-kang1-kang1, ‘in good health’, cf. 健康 jian4-kang1, ‘health’. The other construction (henceforth ABAB) reduplicates the compound, as in 讨论讨论 tao3-lun4-tao3-lun4, ‘discuss a bit’, cf. 讨论 tao3-lun4, ‘discuss’. In standard grammatical descriptions, the functions of these constructions range from expressing vividness, iteration, emphasis, and affect (positive vs. negative), and also depend on part of speech; cf. 热热闹闹 re4-re4-nao0-nao0, ‘very lively’, an adjective, and 热闹热闹 re4-nao0-re4-nao0, ‘liven up’, a verb (see, e.g., Chao, 1968; Lu & Müller, 2026).
From the CCL corpus, a large-scale Chinese corpus containing both modern and classical Chinese materials created by the Center for Chinese Linguistics (Zhan et al., 2019), we extracted all AABB and ABAB constructions, and collected the corresponding embeddings from the Tencent repository (Song et al., 2018). This resulted in a dataset with 1,010 reduplicative constructions, of which 809 have a corresponding two-constituent compound word. We used this dataset, in combination with the general dataset of Yang and Baayen (2025), to address the following research questions. First, do Mandarin reduplications form identifiable regions in a broader distributional semantic space that also contains non-reduplicated Mandarin words? Second, do reduplicative constructions cluster in distributional space by features such as vividness, iteration, emphasis, affect, and part of speech? Third, do AABB and ABAB constructions occupy different regions of semantic space? Fourth, do the meanings of the compounds change when used in reduplicative constructions?
We addressed the first question in two steps. First, we situated the reduplications in a broader lexical semantic space by combining them with the Mandarin reference word set analyzed by Yang and Baayen (2025). This reference set contains 2,173 non-reduplicated Mandarin words from 21 semantic categories. As shown in Figure 1, reduplications are not randomly scattered across this broader space, but are found mostly in the upper right quadrant of the t-SNE plane. The small red cluster in the upper right comprises onomatopoeia. Second, we used linear discriminant analysis (LDA; Venables & Ripley, 2013) to test whether the embeddings distinguish reduplications from reference words. The LDA analysis showed that reduplications can be predicted from the reference words with an accuracy of 98.7% under leave-one-out cross-validation (majority baseline: 68.3%).
Figure 1. The2-D t-SNE plot situating Mandarin reduplications in a broader lexical semantic space together with Mandarin reference words. Reduplications occupy several identifiable regions rather than being randomly scattered among the reference words.
We addressed the second question in two steps. First, unsupervised k-means clustering (Hartigan & Wong, 1979), in combination with linear discriminant analysis (LDA; Venables & Ripley, 2013), revealed 10 robust clusters in distributional space (LDA prediction accuracy with leave-one-out cross-validation: 74.9%, majority baseline: 16.2%). We then carried out semantic profiling using the methods developed by Westbury et al. (2015), Westbury and Hollis (2019), and Westbury and Wurm (2022). To assess valence and personal relevance (Westbury & Wurm, 2022), we calculated the centroids in semantic space of 100 anchor words (e.g., for positive valence, the 100 most frequent words expressing happiness). For unipolar properties, such as personal relevance, we calculated, for each individual reduplication, the cosine similarity between its embedding and the centroid of the embeddings of the anchor-words for personal relevance. For bipolar properties, such as Happy–Sad, Anger–Fear, and Surprise–Disgust, we constructed a semantic axis from the difference between two opposing centroids and projected each individual reduplication onto that axis. For part of speech, cosine similarities were calculated for the centroids of the highest-frequency nouns, verbs, and adjectives in the corpus. Figure 2 presents the constructions in a 3-D t-SNE space, and illustrates the semantic profiling by valence: two clusters (2 and 5) are dominated by words with high scores for happiness. The former cluster comprises ABAB constructions, and the latter cluster comprises AABB constructions.
Figure 2. The 3-D t-SNE plot illustrating semantic profiling of the embeddings of reduplications by valence: Cluster 2 has ABAB reduplications, and Cluster 5 has AABB reduplications. Both score high on positive valence.
Figure 3 addresses our third research question. It presents the embeddings of the constructions in a 2-D t-SNE plane, with color highlighting construction type. There are regions in this plane where only one of the construction types is present. LDA prediction accuracy for construction type is 92.6% (majority baseline: 51.49%). This provides clear evidence that the two kinds of constructions have differentiated functions. For instance, the conditional probability of the ABAB construction given that it is a verbal construction is 99.6%, whereas the conditional probability of the AABB construction given that it is an adjectival construction is 84.9%.
Figure 3. The 2-D t-SNE plot of the embeddings of Mandarin reduplications, with color highlighting construction type (green: AABB, blue: ABAB).
Figure 4 addresses the fourth research question. It presents the constructions in the space of their shift vectors (the embeddings of the constructions from which the embeddings of the base words have been subtracted). Observations are coded by the clusters identified for the embedding space. The shift vectors for cluster 2 (realizing tentativeness semantics) form a tight cluster at the bottom of the graph (blue) and support strong isomorphy between base words and constructions. By contrast, the words of cluster 1 are widely dispersed in the upper half of the t-SNE plane of the shift vectors, and differ from their base words with respect to whether the intensification involves iteration (red dots in the uppermost cluster, e.g. 一只一只 yi1-zhi1-yi1-zhi1, ‘one by one’, cf. 一只 yi1-zhi1, ‘one’), extensification (red dots in the middle right, e.g., 山山水水 shan1-shan1-shui3-shui3, ‘scenery with hills and waters’, cf. 山水 shan1-shui3, ‘mountain and water’), or intensity (red dots in the middle left, e.g., 密密实实 mi4-mi4-shi2-shi2, ‘concentrated’, cf. 密实 mi4-shi2, ‘dense’).
Figure 4. The 2-D t-SNE plot of shift vectors, color coded for the clusters identified by the k-means clustering of the embeddings of the reduplications. The blue cluster at the lower center is an example of instances that cluster both in the embedding space and in the shift space, which is indicative of high semantic transparency.
These analyses illustrate the usefulness of embeddings for coming to a more precise understanding of the interaction of lexis and grammar in Mandarin Chinese.
References
Chao, Y.-R. (1968). A grammar of spoken Chinese. University of California Press.
Hartigan, J. A., & Wong, M. A. (1979). Algorithm AS 136: A k-means clustering algorithm. Journal of the Royal Statistical Society. Series C (Applied Statistics), 28(1), 100–108.
Lu, Y., & Müller, S. (2026). Deliminative verbal reduplication in Mandarin Chinese. Journal of Linguistics. Published online.
Song, Y., Shi, S., Li, J., & Zhang, H. (2018). Directional skip-gram: Explicitly distinguishing left and right context for word embeddings. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers) (pp. 175–180). Association for Computational Linguistics.
Venables, W. N., & Ripley, B. D. (2013). Modern applied statistics with S. Springer Science & Business Media.
Westbury, C., & Hollis, G. (2019). Conceptualizing syntactic categories as semantic categories: Unifying part-of-speech identification and semantics using co-occurrence vector averaging. Behavior Research Methods, 51(3), 1371–1398.
Westbury, C., Keith, J., Briesemeister, B. B., Hofmann, M. J., & Jacobs, A. M. (2015). Avoid violence, rioting, and outrage; approach celebration, delight, and strength: Using large text corpora to compute valence, arousal, and the basic emotions. Quarterly Journal of Experimental Psychology, 68(8), 1599–1622.
Westbury, C., & Wurm, L. H. (2022). Is it you you’re looking for? Personal relevance as a principal component of semantics. The Mental Lexicon, 17(1), 1–33.
Yang, Y., & Baayen, R. H. (2025). Comparing the semantic structures of lexicon of Mandarin and English. Language and Cognition, 17, e10, 1–30.
Zhan, W., Guo, R., Chang, B., Chen, Y., & Chen, L. (2019). The building of the CCL corpus: Its design and implementation. Corpus Linguistics, 6(1), 71–86.