2026
MEETING #20: Friday 6 March 2026, 10:00-11:30 am
Topic: LLMs, Corpus Linguistics, and Language Learning
Peter Crosthwaite (University of Queensland, Australia)
Corpora, Prompts, and Pedagogy: Human-AI Text Comparison in Applied Linguistics
Generative AI has fundamentally disrupted corpus linguistics by making it possible to create large, readily generable corpora of machine-produced text, challenging long-standing assumptions about what constitutes a “natural” language dataset. In response, a growing body of corpus-based research has begun to examine the linguistic characteristics of AI-generated texts, often comparing them with human writing to identify similarities, differences, and potential risks for language education and assessment.
Drawing on my own corpus-based analyses, this talk first revisits findings showing that AI-generated academic texts do not reliably approximate human-like stance, particularly in how evaluation, commitment, and authorial presence are expressed. These results complicate claims that AI writing is simply more “expert-like” or rhetorically mature than student writing. However, more recent work extends this line of inquiry by demonstrating that many of the features attributed to AI texts are strongly conditioned by the prompts used to generate them, including task descriptions, genre cues, and implicit assessment criteria.
Taken together, these studies suggest that differences between human and AI writing are neither fixed nor intrinsic, but emerge from the interaction between prompts, tasks, and evaluative expectations. The talk concludes by considering whether this insight opens productive possibilities for language teaching, asking whether corpus-driven data-driven learning approaches can be meaningfully combined with AI-mediated tools to support learner noticing, agency, and writing development, rather than positioning corpora and AI as competing paradigms.
MEETING #19: Friday 6 February 2026, 2:00-3:30 pm
Topic: Discourse Oriented Corpus Studies
Dan Malone (Edge Hill University, UK)
From Global Uncertainty to Domestic Danger: The lone wolf terrorist as a topos of threat in (poly)crisis discourses
Crises arise amidst uncertainty and are characterised, alongside urgency, by a sense of threat (Lipscy 2020). Few figures embody uncertainty more vividly than the lone-wolf terrorist. Acting in isolation and without formal ties to organised groups, the lone-wolf terrorist has become increasingly prominent in public discourse over the past 15 years (Malone, 2025).
In this talk, I explore how the lone-wolf terrorist emerges in the construction of polycrises in the UK press. Polycrises are understood here, following Krzyżanowski et al. (2023: 423), as the “combination of many, more or less simultaneous and overlapping, crises whose repercussions unfold in a cumulative manner”. Their discursive construction thus relies on how crises are presented as interacting, exacerbating, and reshaping one another (cf. Janzwood & Homer-Dixon, 2022: 4). Specifically, I focus on how the lone-wolf terrorist is rhetorically employed as a topos of threat, operating under the premise that if there is a risk or danger, action must be taken to prevent it (Wodak 2001; Boukala, 2016).
I draw on analyses from the Lone Wolf Corpus (Malone, 2026), a topic-specific corpus of UK newspaper articles featuring the lone-wolf terrorist, focusing on the years 2020 to 2024. The analytical approach employs three interrelated stages to identify collocations and semantic preferences of the lemma lone wolf, as well as discourse prosodies, that is, implicit and explicit attitudes (Stubbs, 2001) towards the lone-wolf terrorist. In the discussion, I pay particular attention to the role of metaphor clusters, viewing metaphor as a device for expressing evaluation implicitly (Martin & White, 2005).
Findings show that the lone-wolf terrorist is a recurring evaluative resource through which crisis events are connected and presented as threatening. From Iran’s nuclear ambitions, Hamas’s activities, and Russia’s aggression in Ukraine, to mass migration, the climate crisis, and fears of radicalisation fuelled by AI and intensified by COVID-19 lockdowns, the lone-wolf terrorist emerges to recontextualise international events as matters of domestic security, transforming global uncertainty into a sense of danger for UK audiences. In this way, otherwise discrete events are discursively construed and rendered as potential polycrises through imagined terroristic violence.
References
Boukala, S. (2016). Rethinking topos in the discourse-historical approach: Endoxon seeking and argumentation in Greek media discourses on “Islamist terrorism”. Discourse Studies, 18(3), 249–268. https://doi.org/10.1177/1461445616634550
Fairclough, N. (1989). Language and power. Longman.
Hjermann, A. R., & Wilhelmsen, J. (2025). Topos of threat and metapolitics in Russia’s securitisation of NATO post-Crimea. Review of International Studies, Advance online publication, 1–20. https://doi.org/10.1017/S0260210524000937
Hoey, M. (2005). Lexical priming: A new theory of words and language. Routledge.
Krzyżanowski, M., Wodak, R., Bradby, H., Gardell, M., Kallis, A., Krzyżanowska, N., Mudde, C., & Rydgren, J. (2023). Discourses and practices of the “new normal”: Towards an interdisciplinary research agenda on crisis and the normalization of anti- and post-democratic action. Journal of Language and Politics, 22(4), 415–437. https://doi.org/10.1075/jlp.23024.krz
Janzwood, S., & Homer-Dixon, T. (2022). What is a global polycrisis? And how is it different from systemic risk? Discussion paper. Cascade Institute.
Janzwood, Scott, and Thomas Homer-Dixon. 2022. What Is a Global Polycrisis? And How Is It Different From Systemic Risk? Discussion Paper.
Lipscy, P. Y. (2020). COVID-19 and the politics of crisis. International Organization, 74(S1), E98–E127. https://doi.org/10.1017/S0020818320000375
Malone, D. (2025). The discourse presentation of the lone-wolf terrorist in the British press, 2000–2019: A corpus-based study (Doctoral dissertation, Edge Hill University).
Malone, D. (2026). Topic-specific corpus compilation: A componential approach to query formulation. Applied Corpus Linguistics, 6(1), 100180. https://doi.org/10.1016/j.acorp.2025.100180
Martin, J. R., & White, P. R. R. (2005). The language of evaluation: Appraisal in English. Palgrave Macmillan.
Stubbs, M. (2001). Words and phrases: Corpus studies of lexical semantics. Blackwell.
Wodak, R. (2001). The discourse-historical approach. In R. Wodak & M. Meyer (Eds.), Methods of critical discourse analysis (pp. 63–95). Sage.
2025
MEETING #18: Friday 19 December 2025, 2:00-4:00 pm
Topic: Philosophies of Language and Corpus Linguistics
Alan Partington (SiBol Group/CoLiTec, Italy)
Language Distrusted, Language Ignored, Language Recovered: From Plato to Corpus Linguistics and Beyond
I wish to discuss the Long Essay, A Short History of the Philosophies Underpinning Corpus Linguistics: From Aristotle to AI, which traces the intertwined histories of linguistic and philosophical thought that shaped—and sometimes resisted—the emergence of corpus linguistics. The heavily revised, updated and now illustrated edition is free to download: https://doi.org/10.5281/zenodo.17998000
New themes include:
• Metaphorophobia in classical philosophy.
• How and why CL can fruitfully cohabit and collaborate with AI/LLMs
• Ontological and epistemological differences between CL, CaDS and LLMs. LLMs: just artefacts or self-organising organisms (Kant)?
• How AI learns metaphorical usage and evaluation. Are there patterns of creative language (including humour) that AI can acquire then use?
• CL as a physical and a human science: causality (Bacon) versus teleology (Aristotle)
• CL/CaDS and the revenge of evaluation, from Hunston to evaluative cohesion.
Alan Partington has taught linguistics at the Universities of Bologna and Camerino, Italy. He is the author of Patterns and Meanings, co-author of Patterns and Meanings in Discourse (both John Benjamins) and author of The Linguistics of Political Argument, The Linguistics of Laughter and The Language of Persuasion in Politics and the Media (all Routledge). He was the co-founding Editor-in Chief of the Journal of Corpora and Discourse Studies. Contact: [email protected]
MEETING #17 Thursday 13 November 2025, 3-5 pm (GMT)
Topic: LLMs and Corpus Tools
Mark Davies (English-Corpora.org, USA)
Integrating information from AI / LLMs into English-Corpora.org
In March 2025 I released seven detailed studies that discuss how well the predictions from LLMs (Large Language Models) match the actual data from large, well-known, publicly-accessible corpora (like those from English-Corpora.org). The seven detailed studies dealt with word frequency, phrase frequency, collocates, comparing words (via collocates), genre-based variation, historical variation, and dialectal variation.
But it’s probably not a question of “either/or with corpora and AI; rather it is probably an issue of “and/with”. Why not take the strengths of AI / LLMs and integrate them right into the corpus interface? As the comparisons between corpora and AI/LLMs indicate, what LLM are really good at is classifying and explaining linguistic data.
So as of September 2025, English-Corpora.org allows users to combine the depth and reliability of corpus data with the analytic power of LLMs like GPT, Gemini, Claude, Perplexity, Llama, Mistral, and DeepSeek. With just one click, the corpus can send collocates, frequency patterns, phrase lists, or concordance lines to an LLM via an “API call”, and then the LLM instantly groups, explains, and interprets the data, and returns that to the corpus. These AI-powered insights appear directly in the interface, alongside the original corpus results (while still keeping it very clear which is the corpus data, and which are the AI categorizations or analyses).
The following are the types of analyses / categorizations that are now available to end users:
- Classifying and categorizing collocates, such as collocates of cap or identity
- Classifying and categorizing phrases, such as soft NOUN
- Comparing two words (via collocates), such as quandary vs predicament
- Comparing genres, time periods, and dialects (two sections), such as chain + NOUN (fic / acad), ADJ women (1800s / now), or ADJ scheme (US / UK)
- Comparing genres, time periods, and dialects (all sections), such as soft NOUN (genres), ADJ food (historical), or *ism words (dialects)
- Comparing genres, time periods, and dialects (charts), such as the “like construction” (genres), need NEG (historical), or soft day (dialects)
- Analyzing KWIC/concordance lines, such as the patterns for fathom or naked eye (including collocations, semantic prosody, syntactic patterns, and pragmatic functions)
- Generating words and phrases for topics and concepts, such as: climate change, famous actresses, or female jobs in 1800s
- Generating words and phrases via translations, such as German sowohl alt als jung, Russian финансовое состояние, or Korean중요한 사안
- Generating words and phrases to find “more natural” phrases, such as make a photo (perhaps from Japanese 写真を撮る), pleasing scenery, or tough idea
Users can also seamlessly move from one LLM to another, they can see the results in any one of 30 different languages, and they can create a simple “AI profile” (e.g. learner, teacher, translator, or linguist), which helps the AI to provide even more customized and helpful results.
English-Corpora.org already has the most widely used online corpora. But with these new AI-powered features, the corpora should be even more useful for teachers, learners, and researchers.
MEETING #16 Friday 2 May 2025, 2:00-3:30 pm
Topic: LLMs and Lexical Priming Theory
Michael Pace-Sigge (University of Eastern Finland)
Large-Language-Model Tools and the Theory of Lexical Priming: Where technology and human cognition meet and diverge
This paper revisits Michael Hoey’s Lexical Priming Theory (2005) in the light of recent discussions of Large Language Models as forms of machine learning (commonly referred to as AI), which have been the centre of a lot of publicity in the wake of tools like OpenAI’s ChatGPT or Google’s BARD/Gemini. Historically, theories of language have faced inherent difficulties, given language’s exclusive use by humans and the complexities involved in studying language acquisition and processing. The intersection between Hoey’s theory and Machine Learning tools, particularly those employing Large Language Models (LLMs), has been highlighted by several researchers. Hoey’s theory relies on the psychological concept of priming, aligning with approaches dating back to Ross M. Quillian’s 1960s proposal for a “Teachable Language Comprehender.” The theory posits that every word is primed for discourse based on cumulative effects, a concept mirrored in how LLMs are trained on vast corpora of text data.
This paper tests LLM-produced samples against naturally (human-)produced material in the light of a number of language usage situations, investigates results from A.I. research and compares the results with how Hoey describes his theory. While LLMs can display a high degree of structural integrity and coherence, they still appear to fall short of meeting human-language criteria which include grounding and the objective to meet a communicative need.
References
Hoey, M. (2005). Lexical Priming. London: Routledge.
Hoey, M. (2009). Corpus-driven approaches to grammar. In: Römer, U. & Schulze, R: Exploring the lexis-grammar interface. Amsterdam/Philadelphia: John Benjamins.pp. 33-47.
Pace-Sigge, M. & Sumakul, T. (2022). What Teaching an Algorithm Teaches When Teaching Students How to Write Academic Texts. In Jantunen, Jarmo Harri, et al. Diversity of Methods and Materials in Digital Human Sciences. Proceedings of the Digital Research Data and Human Sciences DRDHum Conference 2022.
Quillian, R. M. (1967). Word concepts: A theory and simulation of some basic semantic capabilities. Behavioural Science, 12(5), 410-430. https://doi.org/10.1002/bs.3830120511
Tools
Brezina, V. & Platt, W. (2023) #LancsBox X, Lancaster University, http://lancsbox.lancs.ac.uk.
Google [2023] (2024). BARD/Gemini. https://BARD.google.com/chat
OpenAI. [2022] (2024) ChatGPT.(GPT 3.5) https://chat.openai.com/
Scott, M. (2023). WordSmith Tools version 8, Stroud: Lexical Analysis Software.
MEETING #15 Friday 7 March 2025, 3:15-4:30 pm
Topic: LLMs
Yannis Korkontzelos and Amir Amini (Edge Hill University)
Detecting Text Generated by Large Language Models: A novel statistical technique to address paraphrasing
Controlling illegitimate usage of AI in a multitude of educational and professional contexts requires automated systems able to detect text generated by Large Language Models (LLMs) and to distinguish it from human writing samples. Current techniques perform well, unless the text has been automatically paraphrased. In this talk, we will discuss research jointly conducted with Mr Amir Amini. We will start with exploring paraphrasing; how much it can diminish the accuracy of detectors of AI-generated text and we will explain why.
We will identify a property of the probability functions in large language models (LLMs) that can be useful for detecting LLM-generated text, even after paraphrasing. Then, we embed it in a state-of-the-art detector, DetectGPT (Mitchell et al., 2023), to form a new technique for detecting text generated by a particular LLM. We will discuss experiments ad results that demonstrate that this technique is more robust against paraphrasing attacks compared to recently introduced techniques, including DetectGPT and LogRank.
References
E. Mitchell, K. Yoon-Ho Alex Lee, A. Khazatsky, C.D. Manning, and C. Finn. DetectGPT: Zero-shot machine-generated text detection using probability curvature. arXiv (Cornell University), 2023.
Sebastian Gehrmann, Hendrik Strobelt, and Alexander Rush. GLTR: Statistical detection and visualization of generated text. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics: System Demonstrations, pages 111–116. Association for Computational Linguistics, 2019.
X. Hu, P.-Y. Chen, and T.-Y. Ho. Radar: Robust ai-text detection via adversarial learning. Advances in Neural Information Processing Systems, 2023.
Y. Li, Q. Li, L. Cui, W. Bi, L. Wang, L. Yang, S. Shi, and Y. Zhang. Deepfake text detection in the wild. arXiv (Cornell University), 2023.
C. Opara. Styloai: Distinguishing ai-generated content with stylometric analysis. In International Conference on Artificial Intelligence in Education. Springer Nature Switzerland, 2024.
J. Su, T. Zhuo, D. Wang, P. Nakov, and CSIRO’s Data61. DetectLLM: Leveraging log rank information for zero-shot detection of machine-generated text. arXiv preprint, arXiv:2306.05540, 2023.
Y. Zhou and J. Wang. Detecting AI-generated texts in cross-domains. In Proceedings of the ACM Symposium on Document Engineering 2024, pages 1–4, 2024.
MEETING #14: Friday 24 January 2025, 2:00-3:30 pm (GMT), online (MS Teams)
Topic: Corpus Methodology, Multi-Dimensional Analysis
Elen Le Foll (University of Cologne, Germany)
Modelling Textbook English using a Modified Multi-Feature/Dimensional Analysis (MDA) Framework
English as it is represented in secondary school English as Foreign Language (EFL) textbooks is often perceived as somehow different from ‘real-life’, ‘authentic’ English. Indeed, previous studies have shown that individual lexico-grammatical features are often misrepresented (see Le Foll 2024 for a synthesis of the literature). This is problematic given that textbooks are an important and highly influential vector of foreign language input in secondary education. It is therefore worth asking: Does Textbook English constitute a special variety of English? And, if so, in what ways does it differ from ‘real-life’, extra-curricular English?
This talk focuses on the modified version of the multi-feature/multi-dimensional analysis (see Biber 1988; Berber Sardinha & Veirano Pinto 2014; 2019: 19) framework used to answer these questions in Le Foll (2024). MDA is used to compare the language of nine series of EFL textbooks used at in lower secondary education in Germany, France and Spain with three target language reference corpora. Inspired by Diwersy et al. (2014) (2014) and Neumann & Evert (2021), this modified MDA framework is based on principal component analysis (PCA) and extensive multi-dimensional visualisations. The framework further incorporates additional steps designed to increase both the reproducibility and replicability of the results.
Following a theoretical introduction to both the research questions at hand and the MDA framework, the open-source tools used to conduct MDAs in this study are presented from a practical point of view. Together, we examine the functionalities of the Multi-Feature Tagger of English (MFTE Le Foll 2021; see also Le Foll & Shakir 2023) and a number of useful R libraries. To this end, we draw on the RMarkdown scripts that are part of the Online Supplements of Le Foll (2024; https://elenlefoll.github.io/TextbookMDA). Finally, we discuss the steps taken to improve the reproducibility and replicability of the results, in line with the principles of Open Science.
References
Berber Sardinha, Tony & Marcia Veirano Pinto (eds.). 2014. Multi-Dimensional Analysis, 25 Years on: A Tribute to Douglas Biber (Studies in Corpus Linguistics 60). Amsterdam: John Benjamins.
Berber Sardinha, Tony, Marcia Veirano Pinto, Cristina Mayer, Maria Carolina Zuppardi & Carlos Henrique Kauffmann. 2019. Adding Registers to a Previous Multi-Dimensional Analysis. In Tony Berber Sardinha & Marcia Veirano Pinto (eds.), Multi-Dimensional Analysis: Research Methods and Current Issues, 165–188. New York, NY: Bloomsbury.
Biber, Douglas. 1988. Variation across speech and writing. Cambridge: Cambridge University Press. https://doi.org/10.1017/CBO9780511621024.
Diwersy, Sascha, Stephanie Evert & Stella Neumann. 2014. A weakly supervised multivariate approach to the study of language variation. In Benedikt Szmrecsanyi & Bernhard Wälchli (eds.), Aggregating dialectology, typology, and register analysis: Linguistic variation in text and speech, 174–204. Berlin: De Gruyter.
Le Foll, Elen. 2021. Introducing the Multi-Feature Tagger of English (MFTE). Perl. Osnabrück University. https://github.com/elenlefoll/MultiFeatureTaggerEnglish. (5 January, 2022).
Le Foll, Elen. 2024. Textbook English: A Multi-Dimensional Approach (Studies in Corpus Linguistics 116). Amsterdam: John Benjamins.
Le Foll, Elen & Muhammad Shakir. 2023. Introducing a New Open-Source Corpus-Linguistic Tool: The Multi-Feature Tagger of English (MFTE). Presented at the ICAME44, NWU Vanderbijlpark (South Africa).
Neumann, Stella & Stephanie Evert. 2021. A register variation perspective on varieties of English. In Elena Seoane & Douglas Biber (eds.), Corpus-based approaches to register variation (Studies in Corpus Linguistics 103), 144–178. Amsterdam: Benjamins.
2024
MEETING #13: Friday 15 November 2024 (Two presentations)
Topic: Discourse-Oriented Corpus Studies
Katia Adimora (Edge Hill University)
Mexican immigration/immigrants in American and Mexican newspapers
The study employed Corpus Assisted Discourse Studies (CADS) methodology to conduct discourse prosody analysis to reveal hidden attitudes towards Mexican immigration/immigrants in American and Mexican press. It created American immigration corpus (AIC) and Mexican immigration corpus (MIC). The AIC includes 12,595 articles (16,619,925 words) from: The New York Times, The Washington Post, USA Today, Los Angeles Times, The Arizona Republic, Chicago Tribune. The MIC includes 20,865 articles (12,258,123 words) from: El Universal, Elimparcial.com, Reforma, El Norte, Lacronica.com, and Mural.
The results suggest that positive attitudes towards Mexican immigration/immigrants surpass negative attitudes in both corpora, with MIC newspapers being more positive than AIC newspapers, which does not always coincide with public opinion. The attitudes fluctuated during the study period and seemed to correlate with socio-political events and the political leaning of newspapers. In addition, while AIC newspapers were more prone to use impersonal thematic frames to describe immigration issues, MIC newspapers were more likely to use personal episodic frames, which might contribute to more empathy towards Mexican immigrants among the Mexican readership.
The most frequent positive attitudes in both corpora were opposition to Trump’s and Republican anti-immigration policies, and favourable comments towards the rights of immigrants and pro-immigration laws and regulations.
On the other hand, portraying immigrants as criminals was the most frequent negative attitude in both corpora. Also, common negative attitudes in both corpora expressed support for Trump’s anti-immigrant policies, opposed pro-immigrant rules and regulations, and criticised the (perceived) high number of immigrants.
In AIC newspapers, ‘illegal immigrant(s)’ was used with negative discourse prosody, whereas in MIC newspapers, the term ‘inmigrant(es) illegal(es)’ expressed neutral (positive and negative) attitudes.
Dan Malone (Edge Hill University)
When is the extreme also typical? Using prototypicality to investigate representations of the lone-wolf terrorist
The term lone wolf figuratively conjures an image of an individual acting in isolation, perhaps motivated by a desire to break from societal norms. When applied to terrorism, lone wolf draws attention to the perceived aloneness of the perpetrator. However, evidence from the Lone Wolf Corpus (Malone, 2020) reveals that representations in the British press showed notable diachronic trends in how the lone-wolf terrorist’s (LWT) aloneness was (re)presented, which in turn indexed broader discursive shifts.
In this presentation, I report on my approach to investigating representations of the LWT by adopting a prototypical categorisation framework to analysing discourse prosodies (i.e., implicit and explicit attitudes) (Stubbs, 2001: 66) of connection. This categorisation hinges on four key attributes identified during manual corpus annotation: (1) perpetration, (2) ideological motivation, (3) logistical support, and (4) resource provision. These attributes address whether the LWT was represented as operating in complete isolation or receiving some form of assistance, either direct or indirect, from individuals or organisations.
Five distinct connection types emerged from the data, reflecting different combinations of these attributes: the Prototypical Lone Wolf Terrorist, depicted as ideologically self-driven and operationally independent; Assisted by Non-Affiliated Individual(s); Inspired by Organisation; Informed by Organisation; Directed by Organisation; and Member of Organisation. Each connection type was quantified, and its frequency was statistically analysed to trace diachronic discursive shifts.
The findings reveal a discursive reconstruction of the LWT over time. In the early period (2010-2014), the LWT was more frequently presented as a solitary actor, but later portrayals (particularly during 2015-2017) increasingly associated the lone wolf with broader, often Islamist, networks. This shift resulted in the LWT being depicted not as a fully independent individual, but rather as institutionalised and depersonalised—a faceless agent acting on behalf of extremist organisations.
References
Malone, D. (2020) Developing a complex query to build a specialised corpus: Reducing the issue of polysemous query terms. Paper presented at Corpora and Discourse International Conference 2020, University of Sussex, UK.
Stubbs, M. (2001). Words and phrases: Corpus studies of lexical semantics. Blackwell.
MEETING #12: Thursday 25 April 2024
Topics: Corpus Methodology, Large Language Models
Sylvia Jaworska (University of Reading, UK) & Mathew Gillings (Vienna University of Economics and Business, Austria)
How humans vs. machines identify discourse topics: an exploratory triangulation
Identifying discourses and discursive topics in a set of texts has not only been of interest to linguists, but to researchers working across social sciences. Traditionally, these analyses have been conducted based on small-scale interpretive analyses of discourse which involve some form of close reading. Naturally, however, that close reading is only possible when the dataset is small, and it leaves the analyst open to accusations of bias and/or cherry-picking.
Designed to avoid these issues, other methods have emerged which involve larger datasets and have some form of quantitative component. Within linguistics, this has typically been through the use of corpus-assisted methods, whilst outside of linguistics, topic modelling is one of the most widely-used approaches. Increasingly, researchers are also exploring the utility of LLMs (such as ChatGPT) to assist analyses and identification of topics. This talk reports on a study assessing the effect that analytical method has on the interpretation of texts, specifically in relation to the identification of the main topics. Using a corpus of corporate sustainability reports, totalling 98,277 words, we asked 6 different researchers, along with ChatGPT, to interrogate the corpus and decide on its main ‘topics’ via four different methods. Each method gradually increases in the amount of context available.
Method A: ChatGPT is used to categorise the topic model output and assign topic labels;
Method B: Two researchers were asked to view a topic model output and assign topic labels based purely on eyeballing the co-occurring words;
Method C: Two researchers were asked to assign topic labels based on a concordance analysis of 100 randomised lines of each co-occurring word;
Method D: Two researchers were asked to reverse-engineer a topic model output by creating topic labels based on a close reading.
The talk explores how the identified topics differed both between researchers in the same condition, and between researchers in different conditions shedding light on some of the mechanisms underlying topic identification by machines vs humans or machines assisted by humans. We conclude with a series of tentative observations regarding the benefits and limitations of each method along with suggestions for researchers in selecting an analytical approach for discourse topic identification. While this study is exploratory and limited in scope, it opens up a way for further methodological and larger scale triangulations of corpus-based analyses with other computational methods including AI.
MEETING #11: Thursday 29 February 2024
Topic: Corpus Methodology
Matteo Di Cristofaro (University of Modena and Reggio Emilia, Italy)
One dataset, many corpora: Problems of scientific validity in corpora and corpus-derived results
Corpus linguistics has, since its inception, recognised the relevance of digital technologies as a major driving force behind corpus techniques and their (r)evolution in the study of language (cf. Tognini-Bonelli 2012). And yet, while both corpus linguistics and digital technologies have frequently benefited from each other (the case of NLP/NLU is one such macro example), their pathways have often diverged. The result is a disconnect between corpus linguistics and digital data processing whose effects directly impinge on the ability to analyse language through software tools. A disconnect becoming more and more relevant as corpus linguistics is being applied to vast amounts of data obtained from manifold sources – including a wide array of social media platforms, each one with its unique linguistic and technical peculiarities.
As the ground-truth of an ever-increasing number of language studies, corpora must be able to correctly treat and represent such peculiarities: e.g. the dialogic dimension of comments or forum posts; the presence (and potential subsequent normalisation) of spelling variations; the use of hashtags and emojis. Failing to do so, the corpus-derived results will likely present researchers with a falsified view of the language under scrutiny.
What is at stake is not the ability to “count” what is in a corpus, but rather whether what is being counted is or is not a feature present in the original data – of which the corpus should be a faithful representation.
The presentation is consequently devoted to tackling digital technicalities, i.e. “those notions and mechanisms that – while not classically associated with natural language – are i) foundational of the digital environments in which language production and exchanges occur and ii) at the core of the techniques that are used to produce, collect, and process the focus of investigation, that is, digital textual data.” (Di Cristofaro 2023:5). One such example is represented by character encodings: although at the “core” of the whole corpus linguistics enterprise (cf. McEnery and Xiao 2005; Gries 2016:39,111) – since they allow written language to be processed by a computer and understood by humans -, these are often overlooked at all stages of corpus compilation and analysis, potentially leading linguists to involuntarily tampering with the data and its linguistic contents.
Starting from practical examples, the presentation discusses the implications that digital technicalities have on corpora and their analyses – or rather, what happens when they are not properly treated – while outlining (also in the form of Python scripts and practical tools) potential new pathways that a “digital-aware” perspective of corpus linguistics can open up.
References
Di Cristofaro, Matteo. Corpus Approaches to Language in Social Media. Routledge Advances in Corpus Linguistics. New York: Routledge, 2023. https://doi.org/10.4324/9781003225218.
Gries, Stefan Th. Quantitative Corpus Linguistics with R: A Practical Introduction. 2nd ed. New York: Routledge, 2016. https://doi.org/10.4324/9781315746210.
McEnery, Tony, and Richard Xiao. ‘Character Encoding in Corpus Construction’. In Developing Linguistic Corpora: A Guide to Good Practice, edited by Martin Wynne, 47–58. Oxford: Oxbow Books, 2005. https://users.ox.ac.uk/~martinw/dlc/index.htm.
Tognini Bonelli, Elena. ‘Theoretical Overview of the Evolution of Corpus Linguistics’. In The Routledge Handbook of Corpus Linguistics, edited by Anne O’Keeffe and Michael McCarthy, 14–27. Routledge Handbooks in Applied Linguistics. Milton Park, Abingdon, Oxon ; New York: Routledge, 2012.
MEETING #10: Thursday 11 January 2024
Topics: Corpus Methodology, Phraseology
Benet Vincent (Coventry University, UK)
Methodological issues and challenges in the use of phrase-frames to investigate phraseology
[This talk is based on a project in which my collaborators are Lee McCallum & Aysel Şahin Kızıl]
SLIDES | For the video recording, contact Benet Vincent
The importance of gaining a better understanding of phraseology has been recognised for some time now in the area of English for Academic Purposes (EAP). A widespread approach is to extract from a corpus frequently-occurring fixed strings (lexical bundles, or clusters) of potentially useful phrases/multi-word units (see e.g. Gilmore and Millar’s 2018). A limitation of this sort of study is the focus on fixed continuous sequences when phrases are well-known to allow a degree of variation (see e.g. Gries, 2008). One proposal to address this limitation is the ‘phrase frame’ (p-frame), a fixed sequence of items occurring frequently in a corpus with one or two empty slots (Lu, Yoon & Kisselev, 2021). This approach allows researchers to retrieve the most frequent p-frames in a particular corpus, then identify which items typically fill these slots and what meanings / functions might be associated with them. The idea is that the results of such research can help us better understand how members of a specific discourse community typically express themselves, which in turn may inform EAP pedagogy (Lu, Yoon, & Kisselev, 2018). Our project aimed to use a p-frame approach to create a list of pedagogically useful phrases to help novice writers of RA introductions in Health Sciences. A number of studies have used a p-frame approach with similar aims though for different discipline areas, including Fuster-Márquez and Pennock-Speck (2015), Cunningham (2017) and Lu et al., (2018, 2021). However, analysis of these studies indicates that they lack consensus on a number of issues central to p-frame methodology, presenting a challenge for new work in this area. This presentation will provide an overview of the key issues in p-frame research which we have identified and show how we have addressed them. The main aim will be to underline the importance of ensuring that the methods applied by a p-frame study align with the aims of the project.
References
Cunningham, K. J. (2017). A phraseological exploration of recent mathematics research articles through key phrase frames. Journal of English for Academic Purposes, 25, 71. https://doi.org/10.1016/j.jeap.2016.11.005
Fuster-Márquez, M., & Pennock-Speck, B. (2015). Target frames in British hotel websites. International Journal of English Studies, 15(1), 51–69. https://doi.org/10.6018/ijes/2015/1/213231
Gilmore, A., & Millar, N. (2018). The language of civil engineering research articles: A corpus-based approach. English for Specific Purposes, 51, 1–17. https://doi.org/10.1016/j.esp.2018.02.002
Gries, S. (2008). Phraseology and linguistic theory. In Phraseology: An interdisciplinary perspective, S. Granger & F. Meunier (eds.), 3-26.
Lu, X., Yoon, J., & Kisselev, O. (2018). A phrase-frame list for social science research article introductions. Journal of English for Academic Purposes, 36, 76–85. https://doi.org/10.1016/j.jeap.2018.09.004
Lu, X., Yoon, J., & Kisselev, O. (2021). Matching phrase-frames to rhetorical moves in social science research article introductions. English for Specific Purposes, 61, 63–83. https://doi.org/10.1016/j.esp.2020.10.001
Bio-note
Benet Vincent is Assistant Professor in Applied Linguistics at Coventry University in the UK. His research covers applications of corpus linguistics in a range of areas including English for Academic Purposes, Translation, Pragmatics and more generally for the analysis of discourse. He is currently guest editing two special issues for peer-reviewed journals: ‘Corpus Linguistics and the language of Covid-19’ in Applied Corpus Linguistics and ‘Decision-Making in Selecting, Compiling, Analysing and Reporting on the Use of Corpora in Applied Linguistics Research’ in Research Methods in Applied Linguistics
2023
MEETING #9: Thursday 14 December 2023
Topics: Discourse-Oriented Corpus Studies, Collocation Networks
Dan Malone (Edge Hill University, UK) & Hanna Schmück (Lancaster University, UK)
A pack of lone wolves? Exploring the nexus between the lone-wolf terrorist, Al-Qaeda, and ISIS in the British Press
SLIDES | LINK TO OPEN SCIENCE FRAMEWORK PAGE
Following recent events in Belgium and Israel, the lone-wolf terrorist re-emerged in media reportage, with President Joe Biden and former GCHQ Director Sir David Omand expressing concerns over potential attacks in the USA and UK. Days later, Belgian Prime Minister Alexander De Croo described the neutralised Brussels shooter as “probably a lone wolf,” thus aiming to downplay the risk of subsequent incidents. Together, these instances exemplify that by shaping a “reality” (Entman, 2004), (in)security discourses can amplify or downplay a terrorist threat, in turn reflecting and/or influencing public perception and potentially guiding policy responses.
Historically, the lone wolf has been associated with different movements, ranging from the propaganda of the deed in the 19th Century to the leaderless resistance of white-supremacist groups in the 1980s and 90s. More recently, it is within the domain of Islamist terrorism, often dominated by Al-Qaeda and ISIS, where the lone wolf has become increasingly associated, especially in the British press.
In this joint presentation, we discuss the analytical approaches and results from our analysis of discourses surrounding the lone-wolf terrorist, al Qaeda, and ISIS in three diachronic sub-corpora of the Lone Wolf Corpus (Malone, 2020), a compilation of British Press articles from 2000 to 2019. In a unique methodological combination, we employed large-scale collocation networks and topical clustering to examine shifting discourses through collocational clusters, and applied a corpus-based critical discourse analysis to examine representations of the Al-Qaeda-ISIS nexus.
Hanna introduces the methodology employed to generate topical clusters and discusses collocational changes and constants in emerging discourses surrounding the lone-wolf terrorist. The resulting patterns present a discursive shift from clusters related to causative factors (e.g., a mental health subcluster), towards the internationalisation and institutionalisation of lone-wolf terrorism, and finally to response management in the form of sentencing and punitive actions (e.g., a court proceedings/prison subcluster).
Reporting on his corpus-based critical discourse analysis, Daniel presents the emergent representations surrounding co-occurrences of the node AL QAEDA with ISIS. These discourses were categorised into four modes of representation of presented relationship-types: Convergence, Association, Dissociation, and Divergence. These modes contributed to surrounding (in)security discourses that at times equate, promote and/or relegate different entities in a continual reshuffling of the threat hierarchy; a process termed here enmity reimagining.
References
Entman, R. (2004). Projections of Power: Framing News, Public Opinion, and U.S. Foreign Policy. The University of Chicago Press: London.
Malone, D. (2020). Developing a complex query to build a specialised corpus: Reducing the issue of polysemous query terms. Corpora and Discourse International Conference 2020.
MEETING #8: Thursday 9 November 2023
Topic: Discourse-Oriented Corpus Studies, Immigration
Katia Adimora (Edge Hill University, UK)
Towards more positive portrayals of Mexican immigration/immigrants in the American and Mexican press
Various studies (e.g., Galindo Gómez, 2019; Taylor, 2009; Gabrielatos and Baker, 2008) have explored press attitudes towards immigration/ immigrants in different countries. To analyse the attitudes towards Mexican immigration/immigrants in the American and Mexican press, two specialised corpora of 30 million words were created. The American corpus includes more than 12,000 articles from six American newspapers: The New York Times, The Washington Post, USA Today, Los Angeles Times, The Arizona Republic and Chicago Tribune. The corpus articles were published between 16 June 2015, which marked the start of Trump’s presidential campaign, and 20 January 2021, the date of Biden’s presidential inauguration. The Mexican corpus includes more than 20,000 articles from six Mexican newspapers, published during Trump’s era: El Universal, Elimparcial.com, Reforma, El Norte, Lacronica.com and Mural.
Even though the negative discourse prosodies seem to dominate newspaper discourses, this study argues that the attitudes towards Mexican immigration/immigrants in American and, especially, in Mexican newspapers are not as negative as expected. The results show that two-third (66%) of the instances in American corpus newspapers and more than three quarters (78%) of the instances in Mexican corpus newspapers express a positive perspective. However, among the most frequent negative attitudes in American and Mexican corpus newspapers is the description of immigrants as criminals (20% and 18%). The diachronic frequency analysis of the attitudes towards ‘immigration’ and ‘immigrant(s)’ shows correlations between socio-political events and press discourses, which might contribute to public opinion about Mexican immigration/immigrants. For instance, Trump’s family separation policy might have ignited empathy towards immigrants in the corpus newspapers.
MEETING #7: Thursday 30 March 2023
Topic: Corpus Tools & Corpus Processing
Mike Scott (Lexical Analysis Software & Aston University)
News Downloads and Text Coverage: Case Studies in Relevance
Thank goodness it is now quite easy for anyone with the relevant permissions (and patience) to download thousands of text files from online databases such as those of LexisNexis and Factiva. After downloading there are numerous issues to be handled in checking the format of the text, cleaning out remnants of HTML, handling references to images, formulae, reader comments, sorting them by date or source etc.
The problem to be addressed here, however, chiefly concerns a) duplicate contents and b) relevance to the user’s research aims.
News texts in particular suffer increasingly from duplication as minor changes are mad, or as a news story grows hour by hour.
Also, anyone who has looked at such searches will have noticed that some texts are really centrally concerned with the issue being studied, for example the brewing of beer, or the characters in Middlemarch, but others merely make a passing mention, such as “Peter always liked his beer” in an obituary or “most informants reportedly had never read Middlemarch” in a survey of hobbies and interests.
In this presentation, using WordSmith Tools 8.0, I shall attempt to quantify both the degree of content duplication in three sets of text, and the degree of central relevance to a theme.
Bio-note
After teaching English for many years in Brazil and Mexico, Mike Scott moved to Liverpool University in 1990, teaching initially Applied Linguistics generally but then specialising in Corpus Linguistics. In 2009 he moved to Aston University. In the early 1980s he learned computer programming and began to develop corpus software: MicroConcord (1993 with Tim Johns), WordSmith Tools 1996, which is now in version 8. His current field is corpus linguistics, sub-field corpus linguistics programming.
MEETING #6: Thursday 2 March 2023 (Two presentations)
Topic: Manual Annotation in Discourse-Oriented Corpus Studies
Katia Adimora (Edge Hill University)
Annotating Mexican immigration discourses
Discourses of Mexican and American newspapers about Mexican immigration to the US during Trump’s presidency were pragmatically annotated according to the attitudes they express about different semantical aspects of immigrants and immigration, such as border, families, and crime.
Firstly, by deploying the Mexican immigration corpus (in Spanish), American immigration corpus (in English) and corpus tool Sketch Engine (SE), the researcher conducted the search for concordances for the search terms ‘immigration’, ‘immigrant’ and ‘inmigración’ and ‘inmigrante’, respectively. Secondly, the random samples of fifty concordances for each term were extracted. Concordances were transferred to the word table and manual annotated according to the pragmatic perspective they express towards immigrants. After all 200 instance were annotated and no additional attitudes were identified, the annotation scheme with codes for the expressed attitudes and their definitions were created. Attitudes towards immigration were classified into three levels:
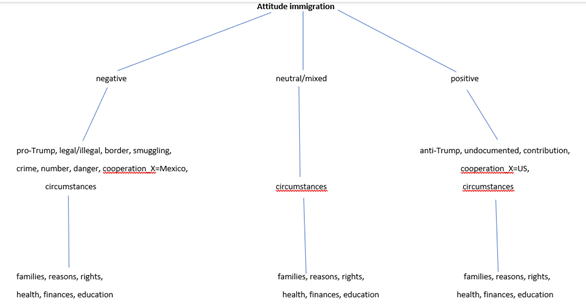
For example, second level ‘attitude positive-anti-Trump’ with a code (Att_ pos-aT) includes instances where the main sentiment is positive towards immigration, which is shown via opposition towards Trump’s anti-immigration policies:
In Fountain Hills, Trump blamed immigrants in the country illegally for “so many killings, so much crime.” He then went after rival presidential candidates Ted Cruz and John Kasich, saying his approach to illegal immigration was tougher than theirs.
Dan Malone (Edge Hill University)
A lone wolf from the ISIS pack: Hunting discourses through manual annotation
The process of manual corpus annotation, where researchers add interpretive information to corpus data, is a valuable tool for systematically analysing linguistic or semantic features in a corpus. A core aspect of manual annotation is the annotation scheme – a set of guidelines for labelling corpus content, including annotation categories, definitions, and examples (McEnery & Hardie 2012: 90).
In this talk, I will introduce the manual annotation approach and annotation scheme I developed for analysing the representations of the nexus between lone-wolf terrorists and the extremist groups ISIS and al Qaeda in the British press. The underpinning goal of this annotation scheme is to systematically reveal discourse prosodies, in other words, the implicit and explicit attitudes (Stubbs 2001: 66) towards the lone-wolf terrorist.
The context for this talk is my doctoral research project “Constructing the Lone Wolf Terrorist: A corpus-based critical discourse analysis.” The dataset used in this study is The Lone Wolf Corpus, a purpose-built corpus consisting of approximately 8.5 million words and 8,600 texts from UK national newspapers, published between 2000 and 2019 (Malone 2020).
I will describe the iterative process used to develop the annotation scheme, which involved cycles of annotation. I will also provide a detailed explanation of the scheme’s four distinct categories and illustrate each category with examples. The first two categories identify the type of entity represented by the node LONE WOLF, as well as the collocates ISIS and AL QAEDA, and determine whether each entity is portrayed as an active and dynamic force (Van Leeuwen, 2008: 33). The third category denotes the connection between the node and the collocate, while the fourth category outlines the discursive link.
Additionally, I will address the practical challenges that arose during the development of the annotation scheme, namely: (1) the need to avoid top-down categorisation, (2) the difficulty of balancing scheme richness with the intensity of labour required for its application, and (3) ensuring the reliability of the coding process.
References
Malone, D. (2020). Developing a complex query to build a specialised corpus: Reducing the issue of polysemous query terms. Corpora and Discourse International Conference 2020. https://doi.org/10.13140/RG.2.2.31214.43846
McEnery, T., & Hardie, A. (2012). Corpus linguistics: Method, theory and practice. Cambridge University Press.
Stubbs, M. (2001). Words and phrases: Corpus studies of lexical semantics. Oxford: Blackwell.
Van Leeuwen, T. (2008). Discourse and Practice: New Tools for Critical Discourse Analysis. Oxford University Press.
2022
MEETING #5: Thursday 15 December 2022
Topic: Corpus Tools & Semi-Automated Annotation
Martin Weisser (University of Salzburg)
Doing Corpus Pragmatics in DART 3
The Dialogue Annotation and Research Tool (DART) is a freeware tool that makes it possible to annotate large amounts of dialogue data semi-automatically on a number of linguistic levels, as well as post-process and analyse the resulting corpora efficiently using various corpus analysis methods. Perhaps arguably, the most interesting and important levels of analysis produced by the tool from the point of view of corpus pragmatics are the syntactic and the speech-act level, but DART annotations also comprise information about the semantics (topics), semantico-pragmatic (modes; Searle’s IFIDs), surface polarity, (completion) status, and disfluency of units. In this talk, I want to begin by providing a brief overview of the background, genesis and development of the tool. Next, we’ll discuss the different levels of annotation, their potential significance in pragmatics, and how they may work together in determining the pragmatic meaning potential in the form of speech acts. I’ll then briefly illustrate how it’s possible to adapt the resources used for the annotation process to new domains, as well as the steps involved in the annotation process itself. And last, but not least, we’ll explore the different analysis options related to speech acts and other patterns the tool has to offer.
DART3: https://martinweisser.org/ling_soft.html#DART
MEETING #4: Friday 8 April 2022 (Two presentations)
Topics: Corpus Tools & Manual Annotation
Encarnación Hidalgo-Tenorio (University of Granada) and Miguel-Ángel Benítez-Castro (Universidad de Zaragoza)
Workshop: Manual Annotation with UAM Corpus Tool.
Presentation: Analysing Extremism under the Lens of Appraisal Theory.
Appraisal Theory is aimed to understand how social relations are negotiated through alignment, as linguistically realised by the axes of ENGAGEMENT, GRADUATION and ATTITUDE (Martin & White 2005). Of the three subsystems, the latter has attracted more attention so far. ATTITUDE helps classify instances of emotion/al talk through the meaning domains of AFFECT, JUDGEMENT and APPRECIATION. As argued by White (2004) and Bednarek (2009), emotional talk may entail the more indirect expression of emotion by attending to ethical and aesthetic values. Given the omnipresence of affect in language (including Ochs & Schieffelin 1989; Barrett 2017), there is growing consensus about treating AFFECT as a superordinate category, now taken to include the expression of EMOTION (emotional evaluation) and OPINION (ethical and aesthetic evaluation). As emotion permeates all levels of linguistic description (including Alba-Juez & Thompson 2014; Alba-Juez & Mackenzie 2019), and all utterances are produced and interpreted through emotions (Klann-Delius 2015), AFFECT may be enriched through a more explicit focus on affective psychology, thereby proposing more sharply defined categories that may better describe any instance of emotive language (Thompson 2014). This paper shows how Benítez-Castro & Hidalgo-Tenorio’s (2019) more psychologically-driven Appraisal EMOTION sub-system can lead to a user-generated Appraisal scheme allowing a more fine-grained analysis of the complex interplay between (explicit and implicit) EMOTION and OPINION in discourse. To do so, we draw on examples and findings from two research strands we have covered so far: American right-wing populist discourse (Hidalgo-Tenorio & Benítez-Castro 2021b) and Jihadist propaganda (Benítez-Castro & Hidalgo-Tenorio Forthcoming).
Encarnación Hidalgo-Tenorio is Professor in English Linguistics at the University of Granada, Spain. Her main research area is corpus-based CDA, where she focuses on the notions of representation and power enactment in public discourse. She has published on language and gender, Irish studies, political communication, and has also paid attention to the analysis of the way identity is discursively constructed. She has tried to develop, or reconsider, some interesting aspects taken from SFL such as Transitivity, Modality, or Appraisal. Currently, she is working on the lexicogrammar of radicalization. Address for correspondence: Departamento de Filologías Inglesa y Alemana, Facultad de Filosofía y Letras, Campus de Cartuja s/n, 18071, University of Granada, Spain. <[email protected]>
Miguel-Ángel Benítez-Castro is lecturer in English Language at the University of Zaragoza, Spain. His main research interest lies in SFL-inspired discourse analysis, based on corpus-driven methodologies, which he has managed to apply to his general focus on the interface between lexical choice, discourse structure, and evaluation. This is reflected in his previous and ongoing research on shell-noun phrases, on the evaluation of social minorities in public discourse and on the refinement of SFL’s linguistic theory of evaluation. Address for correspondence: Department of English and German Studies, Facultad de Ciencias Sociales y Humanas, Universidad de Zaragoza, Ciudad Escolar, s/n, 44003 Teruel.
MEETING #3: Wednesday 8 February 2022
Topic: Corpus Tools
Andrew Hardie (Lancaster University)
What’s new in CQPweb – 2022 edition
In this informal workshop / presentation, Andrew Hardie will give an overview of the latest new features in CQPweb version 3.3. This includes, most notably, the option for users to upload their own corpora to the system, tagging the data using either CLAWS or TreeTagger – plus the new system that enables other users on the same server to share access to these uploaded corpora. Participants are welcome to try it out “in real time” during the session.
2021
MEETING #2: Wednesday 15 December 2021
Topic: Corpus Tools & Automated Annotation
Paul Rayson (Lancaster University)
Counting words or wording counts?
A wide variety of tools and methods are available across a number of disciplines (e.g. Education, History, Linguistics, Literature, Psychology) for the analysis of text, and many of the techniques (e.g. content analysis, topic modelling, sentiment analysis) rely on counting words. However, words can take different meanings in different contexts, and around 16% of running text counts as semantically meaningful multiword expressions (where the meaning of the whole expression is different from the collection of individual words). In this talk, I will describe what can be achieved by combining methods from computer science (natural language processing) with linguistics (corpus linguistics) to address these issues. The talk will cover the basics of semantic annotation where words and multiword expressions are automatically labelled with coarse-grained word senses using the UCREL Semantic Analysis System (USAS). Then, via a demonstration of the web-based Wmatrix tool, I will show how counting USAS categories and comparing the frequency profiles with those from other texts can be used to quickly gist a text or corpus. Along the way, I will provide some pointers to example case studies in psychology, political discourse analysis, and beyond, describe current research and development on open source USAS multilingual taggers, and provide attendees with pointers for Wmatrix access and further tutorials to follow up later using your own corpora.
Bio note
I am a Professor in Computer Science at Lancaster University, UK and Director of the UCREL interdisciplinary research centre which carries out research in corpus linguistics and natural language processing (NLP). A long term focus of my work is semantic multilingual NLP in extreme circumstances where language is noisy e.g. in historical, learner, speech, email, txt and other CMC varieties. Along with domain experts, I have applied my research in the areas of dementia detection, mental health, online child protection, cyber security, learner dictionaries, and text mining of biomedical literature, historical corpora, and financial narratives. I was a co-investigator of the five-year ESRC Centre for Corpus Approaches to Social Science (CASS) which is designed to bring the corpus approach to bear on a range of social sciences. I’m also a member of the multidisciplinary Institute Security Lancaster, the Lancaster Digital Humanities Hub, and the Data Science Institute.
MEETING #1: Wednesday 10 November 2021 (Two presentations)
Topic: Constructing Topic-Specific Corpora
Dan Malone (Edge Hill University)
Constructing the Lone Wolf Corpus: Using polysemous query terms to compile a topic-specific corpus
This paper is concerned with the process of developing a query to compile a topic-specific corpus from a text database. For a corpus to be topic-specific, its texts must be relevant to the topic(s) for which it was compiled to investigate. However, polysemous query terms are more likely than monosemous query terms to retrieve nonrelevant texts and, therefore, reduce query precision, that is, the ratio of relevant to nonrelevant texts retrieved. More specifically, then, this paper suggests that the issue of polysemous query terms can be addressed through the implementation of a dual-group complex query (hereafter, DGQ).
The motivation for this paper arose while compiling the corpus for my PhD project ‘Constructing the Lone Wolf Terrorist: A corpus-driven study of the British press’. In its actor-based approach, corpus compilation was underpinned by an onomasiological perspective of the connection between lexical items and the concept of ‘the lone wolf terrorist’. According to Geeraerts (2010: 23), “onomasiology takes its starting point in a concept and investigates the different expressions via which the concept can be designated or named”. This is opposed to semasiology, which “takes its starting point in the word as a form and charts the meanings that the word can occur with” (ibid). Indeed, the concept ‘lone wolf terrorist’ can be expressed via a number of polysemous lexical items, such as lone actor, lone attacker, and solo actor, with the specificity of their meaning being derived from context.
To compile the Lone Wolf Corpus (LWC), rather than employing a simple query-string, the DGQ was devised to mitigate the polysemy of its query terms. It comprises two distinct groups of terms, with each based around a core semantic component of ‘lone-wolf terrorist’; Group A terms represented lone-wolf actors or actions, whereas Group B represented terrorism. By linking terms within each group with the Boolean operator OR and by then linking the two groups using AND, the query retrieved texts containing at least one term from each group. By drawing on textual context in the form of collocation, the potential for multiplicity of meaning of the polysemous query terms is restricted, leading to a reduction in the number of nonrelevant texts being retrieved by the query.
This paper develops the query formulation technique outlined by Gabrielatos (2007). Central to Gabrielatos’s technique is the metric of relative query term relevance (RQTR), which establishes the degree of relevance of candidate query terms to the topic being investigated. The RQTR technique has been adopted in a number of studies, such as Prentice (2010), Dimmroth, Steiger & Schünemann (2017), and Kreischer (2019), as a means to both expanding queries and establishing the relevancy of candidate terms. This paper expands the applicability of the RQTR method by illustrating how it can be applied to the DGQ and, therefore, cater for polysemous query terms.
From the initial core query terms lone wolf and terrorism, the LWC query was expanded to seventy query terms. When applied to the Lone Wolf Corpus (LWC) query, the DGQ improved query precision at minimal expense to recall, relative to a simple query. Based on a systematic sampling, the results show that the DGQ improved precision from 0.46 to 0.89, which was gained at the minimal expense of a 0.08 decrease in retrieved relevant texts.
References
Gabrielatos, C. (2007). Selecting query terms to build a specialised corpus from a restricted access database. ICAME Journal, 31, 5-44.
Geeraerts, D. (2010). Theories of Lexical Semantics. Oxford University Press.
Kreischer, K. S. (2019). The relation and function of discourses: a corpus-cognitive analysis of the Irish abortion debate. Corpora, 14(1), 105-130.
Prentice, S. (2010). Using automated semantic tagging in Critical Discourse Analysis: A case study on Scottish independence from a Scottish nationalist perspective. Discourse & Society, 21(4), 405–437.
Steiger, S., Schünemann, W. J., & Dimmroth, K. (2017). Outrage without consequences? Post-Snowden discourses and governmental practice in Germany. Media and Communication, 5(1), 7-16.
Katia Adimora (Edge Hill University)
Building bilingual corpora for Critical Discourse Analysis: Mexican immigration to the US
This talk will address the building of topic-specific corpora about Mexican immigration to the US during Donald Trump era. The corpora contain American and Mexican newspaper articles that cover Mexican immigration (44,779 articles, 30 million words). The aim is to analyse how immigrants are represented in them.
The newspapers included in the corpora are:
US newspapers: New York Times, Washington Post, USA Today, Los Angeles Times, The Arizona Republic and Chicago Tribune.
Mexican newspapers: El Universal, Elimparcial.com, Reforma, El Norte, Lacronica.com and Mural.
To gather the relevant articles, three-part query was formed based on the reading through various American and Mexican articles, and by identifying the words that are deployed to talk about immigrants or immigration. Bilingual queries: in English and Spanish, needed to be constructed. Spanish query terms are synonyms to English ones, however not necessary the literal translation from English as Mexican newspapers do not use specific expression that is used in English, or they use different expressions to talk about immigration and immigrants.
Articles were transferred from online database ProQuest (Global Newsstream) to the software tool Sketch Engine (https://www.sketchengine.eu/).
American and Mexican corpora were divided in subcorpora to be able to compare how the newspapers in American states with the highest number of Mexican immigrants, represent them in comparison to national newspapers. Similarly, Mexican subcorpora was formed to compare how newspapers from the regions in Mexico with the high number of Mexican migrants that move to the US address them compared to the national newspapers.
These subcorpora division differs from the one commonly applied to the British press, on broadsheets vs. tabloid, and according to political leaning on leftist, rightist and centrist. This is due to the difficulty to draw the line between these types of grouping of American, and especially, Mexican newspapers.
References
Kilgarriff, Adam, Vít Baisa, Jan Bušta, Miloš Jakubíček, Vojtěch Kovář, Jan Michelfeit, Pavel Rychlý, Vít Suchomel (2014) The Sketch Engine: ten years on. Lexicography, 1: 7-36.